

[분류 전체보기]검색결과, 375건
- [C# 기초강좌] 14. C# 연산자 오버로딩 2023.11.20 1
- [C# 기초강좌] 13. C# 상수 선언, const 와 readonly 2023.11.06 43
- [C# 기초강좌] 12. C# 인덱서와 프로퍼티 2023.11.06 4
- [C# 기초강좌] 11. C# 오버로딩과 오버라이딩 그리고 new 2023.11.02 23
- [C# 기초강좌] 10. C# 생성자와 소멸자 2023.11.02
- [C# 기초강좌] 9. C# 배열 2023.11.02 2
- [C# 기초강좌] 8. C# 제어문(조건문과 반복문) 2023.11.02
- [C# 기초강좌] 7. 박싱과 언박싱 2023.11.02 6
- [C# 기초강좌] 6. C# 자료형 2023.11.01 1
- [C# 기초강좌] 5. C#응용프로그램의 기본 골격 2023.11.01 1
- [C# 기초강좌] 4. 명령줄 빌드 2023.11.01 1
- [C# 기초강좌] 2. 닷넷의 실행구조 2023.11.01
- SBCS, MBCS, WBCS 2023.10.31
- 이런... 계집 녀(女) 2023.10.31 6
- 다차원 배열의 인덱싱 2023.10.27
이 글은 제가 과거에 운영했던 사이트인 http://dotnet.mkexdev.net 의 글을 옮겨온 것입니다. 원본 글은 2010년에 작성되었습니다.
그 전에 운영했었던 사이트(mkex.pe.kr)은 흔적도 없이 사라 졌습니다. 그속의 글들도 모두... 그래서 이 사이트도 사라지기 전에 옮기고 싶은 글을 조금씩 이 블로그로 이동시키려 합니다.
(원본글) http://dotnet.mkexdev.net/Article/Content.aspx?parentCategoryID=1&categoryID=5&ID=678
이 글은 닷넷 기초 지식을 전파하기 위해 2010경에 작성되었으며, 당시 윤성우의 프로그래밍 스터디그룹 네이버 카페에도 필진으로 참여하여 연재했던 글이기도 합니다. 현재 시점에서 조금 달라진 부분이 있을 수 있으나 기본 원리와 언어 기초에 해당하는 부분은 크게 변하지 않았을 것으로 생각하며 이런 부분들을 감안해서 봐 주시기 바랍니다.
“연산자 오버로딩, 이것 역시 메서드 입니다”
안녕하세요. 박종명입니다. 닷넷 열네 번째 강좌를 진행하도록 하겠습니다.
이번 강좌는 C#에서 연산자를 새로이 정의할 수 있는 기법인 ‘연산자 오버로딩’에 대해 알아 보겠습니다
연산자 오버로딩은 사칙연산과 같이 기본 제공되는 +, -, *, / 연산자는 물론 비교 연산자, 형 변환 연산자 등을 오버로드 하여 새로운 연산 논리를 구현하는 기법으로써 오버로드 된 연산자 역시 결국에는 메서드입니다.
숫자 형식 데이터를 다루는데 있어 사칙연산은 프로그램의 생명 주기에 상당히 많이 차지하는 기본 연산입니다.
int a = 1; int b = 2;
int sum = a + b;
숫자 형식은 그렇다 치더라도 사용자 정의 자료형인 객체나 구조체끼리의 사칙연산이 가능할까요?
Pserson 이라는 클래스의 객체 person1 과 person2에 대해 다음과 같이 더하기(+) 연산은 가능할까요?
Person p1 = new Person ();
Person p2 = new Person ();
Person sumPerson = p1 + p2;
코드를 실행해 볼 필요도 없이 이 연산은 컴파일 오류를 발생시킵니다.
현실적으로 사람을 추상화 한 Person 객체에 더하기를 수행할 이유는 없어 보입니다. 그러나 만일 정말 만일에, 두 사람을 더하면(+) 두 사람의 나이(age)가 더해져서 반환되도록 해야 한다면 어떻게 하는 것이 좋을까요?
언뜻 AddPerson(Person p1, Person p2) 이라는 메서드를 생각해 볼 수 있습니다.
좋은 선택입니다. 그럼 두 사람이 아닌 셋, 넷, 다섯 사람을 더해야 한다면 아래와 같은 코드가 예상됩니다
Person sumPerson = Person.AddPerson(Person.AddPerson(Person.AddPerson(p1, p2), p3),p4);
코드는 총 4 사람(Person)에 대해 더하기를 수행하고 있습니다.
뭔가 복잡해 보입니다. 숫자를 더하듯 할 수 있다면 간편하지 않을까요? 아래와 같이요.
Person sumPerson = p1 + p2 + p3 + p4;
훨씬 간단해 보입니다. 이것이 가능할까요?
연산자 오버로딩은 바로 이것입니다. 객체와 같은 사용자 정의 타입에 연산자를 새롭게 정의 할 수 있도록 해 주는 기법입니다.
이때 연산자는 사칙연산과 같이 기본 제공되는 연산자 키워드를 기반으로 다시 정의하는 것이기 때문에 연산자 오버로딩이라고 합니다. 메서드 오버로딩이 그러하듯 이요.
복소수 클래스의 연산자 오버로딩
수학에서 복소수라 함은 실수와 허수의 합으로 이루어진 수 인데요. 다음과 같이 표현합니다.
a + bi (a, b는 실수, i2 = -1을 만족하는 허수단위)
복소수의 수학적 개념보다도 우리는 이 복소수를 표현하고 연산하기 위해 프로그램을 작성한다고 가정합니다.
다음과 같이 실수부와 허수부에 해당하는 멤버 변수 2개를 가진 복소수 클래스를 정의하고 생성자를 통해 값을 초기화 합니다. 그리고 ToString() 메서드에서 복소수 표현식인 a + bi 형태로 반환하도록 오버라이딩 해 둡니다.
class Complex{
public int real; //실수부
public int imaginary; //허수부
public Complex(int real, int imaginary) {
this.real = real;
this.imaginary = imaginary;
}
public override string ToString(){
return (System.String.Format("{0} + {1}i", real, imaginary));
}
}
복소수의 사칙 연산
복소수에 사칙연산을 수행할 수 있는데요.
두 복소수 (a + bi) 와 (c + di)의 덧넷, 뺄셈, 곱셈은 다음과 같이 계산할 수 있습니다
덧셈: (a + bi) + (c + di) = (a + c) + (b + d)i
뺄셈: (a + bi) - (c + di) = (a - c) + (b - d)i
곱셈: (a + bi) * (c + di) = (ac - bd) + (bc + ad)i
우리가 정의한 복소수 클래스(Complex)에 이러한 사칙연산을 미리 정의해 두면 이 클래스를 사용하는 입장에서 편리하겠죠. 그리고 클래스 구조적으로도 사칙연산의 행위를 미리 정의해 두는 것이 좋습니다.
물론 메서드를 통해 각각의 연산 메서드를 정의할 수 있겠지만 우리는 연산자 오버로딩을 통해 구현하도록 합니다.
operator X 키워드
연산자 오버로딩을 위해서 사용되는 키워드는 operator 입니다. 그리고 X 부분은 오버로딩할 연산자입니다.
우리는 덧넷,뺄셈,곱셈을 정의할 것이기에 X 는 +, - , * 이 되겠네요
아래 세 연산자를 오버로드 한 코드입니다.
public static Complex operator + (Complex c1, Complex c2){
return new Complex(c1.real + c2.real, c1.imaginary + c2.imaginary);
}
public static Complex operator - (Complex c1, Complex c2){
return new Complex(c1.real - c2.real, c1.imaginary - c2.imaginary);
}
public static Complex operator * (Complex c1, Complex c2){
return new Complex((c1.real * c2.real) - (c1.imaginary * c2.imaginary),
(c1.imaginary * c2.real) + (c1.real * c2.imaginary));
}
세가지 연산이 정의되었기 때문에 다음과 같이 복소수 연산을 일반 연산처럼 쉽게 이용할 수 있습니다.
static void Main(string[] args){
Complex num1 = new Complex(4, 3);
Complex num2 = new Complex(3, 2);
Complex add = num1 + num2;
System.Console.WriteLine("복소수 합: {0}", add);
Complex minus = num1 - num2;
System.Console.WriteLine("복소수 차: {0}", minus);
Complex multi = num1 * num2;
System.Console.WriteLine("복소수 곱: {0}", multi);
}
마치 일반 숫자 데이터의 사칙연산을 하듯이 객체의 사칙연산이 가능해 졌습니다. 물론 메서드로 이러한 연산을 제공해 줄 수도 있지만 연산자 오버로딩을 구현하면 메서드로 처리하는 것보다 직관적이며 명확해져 편리성과 잠재적 버그 유발성을 줄일 수 있는 장점이 있습니다.
연산자 오버로딩 규칙
연산자를 오버로딩하는 언어적 규칙이 몇 가지 있습니다. 이를 소개합니다.
- 연산자 오버로딩은 operator X 키워드로 구현한다.
- 반드시 public 로 정의되어야 한다.
- 반드시 static 로 정의되어야 한다.
- 입력 매개변수 중 하나 이상은 반드시 그 클래스의 형식과 동일해야 한다
public static Complex operator + (Complex c1, int i){ .. } //가능
public static Complex operator + (int i, int j) { .. } //불가능
- 연산자 오버로딩을 다시 오버로딩 할 수 있다.
연산자 오버로딩도 결과적으로는 메서드이다. 따라서 시그너처를 달리 하면 이미 정의된 연산 오버로딩을 다시 오버로딩 할 수 있다. 아래 코드는 더하기(+) 연산자를 시그너처를 달리 하여 두 개 오버로딩 한 예시이다.
public static Complex operator + (Complex c1, Complex c2){
return new Complex(c1.real + c2.real, c1.imaginary + c2.imaginary);
}
public static Complex operator + (Complex c1, int i){
return new Complex(c1.real + i, c1.imaginary + i);
}
연산자 오버로딩도 결국 메서드라 하였는데요.
IL 코드를 보면 덧넷,뺄셈,곱셈에 대한 각각의 연산자 오버로딩이 op_Addition, op_Subtraction, op_Multiply 메서드로 자동 생성된 것을 확인할 수 있습니다.
이렇듯 연산자 오버로딩을 하게 되면 ‘op_예약된심벌’ 형태의 메서드로 치환되는 것입니다.

비교연산자 오버로딩
지금까지는 사칙연산에 대한 연산자 오버로딩을 알아 보았는데요. 연산자 오버로딩은 사칙연산뿐만 아니라 다른 연산자에 대한 오버로딩도 가능합니다.
비교연산자의 오버로딩에 대해 알아 보겠습니다. C#의 비교 연산자는 다음과 같습니다.
1) 동일성 비교
== : 두 값의 일치 여부, != : 두 값의 불일치 여부
2) 크기 비교
< : ‘보다 작음’ 비교, > : ‘보다 큼’ 비교
<=: ‘작거나 같음’ 비교, >= ‘크거나 같음’ 비교
비교연산자를 자세히 보면 모두 쌍으로 이루어져 있습니다. 즉 == 는 != 와 < 는 > 와 쌍을 이루고 있지요.
비교연산자를 오버로딩 할 경우 반드시 이 쌍을 모두 오버로딩 해야 합니다(필수 사항입니다)
예를 들어 == 연산자를 오버로딩 할 경우 반드시 그 쌍을 이루는 != 를 같이 오버로딩 해야 하는 것이죠.
닷넷 프레임워크에서 제공하는 System.String 에서 동일성 비교 연산자를 오버로딩 한 예를 볼 수 있는데요. Msdn에 System.String 클래스의 설명을 보면 아래와 같이 == 와 !=를 오버로딩 한 것을 확인할 수 있습니다.

public static bool operator == (
string a,
string b
)
public static bool operator != (
string a,
string b
)
참고로 동일성 비교 연산자를 오버로딩 할 경우 Object 로부터 상속받는 Equals 메서드도 같은 연산으로 오버라이딩 하는 것이 좋습니다(프로그램 일관성을 위한 권장사항 입니다)
(나아가 Equals 메서드를 오버라이딩 할 경우 GetHashCode 메서드도 오버라이딩 하는 것이 좋습니다)
연산자 오버로딩 가능한 연산자 목록
앞서 살펴본 것과 같이 사칙연산과 비교 연산자는 연산자 오버로딩이 가능합니다. 닷넷의 연산자 중 오버로딩이 가능한 연산자와 일부 제한이 있는 연산자가 있습니다.
다음 표는 msdn 의 설명입니다

형 변환 연산자 오버로딩
마지막으로 형식 변환과 관련된 연산자 오버로딩에 대해 알아 보겠습니다.
연산자 오버로딩은 산술연산자나 비교연산자 외에도 형식(Type) 변환에도 적용할 수 있습니다
특정 자료형을 다른 자료형으로 변환하는 것을 형 변환 이라고 하는데요. 예를 들어 문자열 정수인 int 형의 데이터를 실수인 double 형으로의 형 변환은 다음과 같이 자연스럽게 이루어 집니다.
int iValue = 10;
double dValue = iValue; //묵시적 형변환
특별히 어떤 키워드 없이도 정수형 자료가 실수 형 자료로 할당되었습니다. 이것은 더 작은 자료형에서 큰 자료형으로의 변환은 자동으로 이루어 지는 즉 ‘묵시적 형 변환’ 사례입니다.
반면 실수형 자료를 정수형 자료로 할당하고자 할 경우에는 다음 코드와 같이 반드시 ‘명시적 형 변환’을 해 줘야 합니다.
double dValue = 10d;
int iValue = (int) dValue; //명시적 형변환
명시적 형 변환 위한 ‘(형식)’ 이라는 연산자가 이용된 것입니다.
이것은 클래스의 상속 관계에서도 적용되는데요. ‘부모 ? 자식 클래스’ 구조에서, 자식객체 -> 부모 객체로의 변환은 묵시적으로 이루어 지고 부모객체 -> 자식 객체로의 변환은 명시적으로 형 변환을 해 줘야 합니다.
이러한 묵시적, 명시적 형 변환을 새롭게 정의할 수 있는 것이 형 변환 연산자 오버로딩 입니다.
형 변환 오버로딩의 키워드는 operator X 와 더불어 다음 두 키워드가 사용됩니다.
implicit: 묵시적 형 변환 오버로딩
explicit: 명시적 형 변환 오버로딩
그럼. 형 변환 오버로딩 예를 보겠습니다.
Person이라는 클래스를 정의하고 이름(name)과 나이(age)를 속성으로 가지도록 합니다. 그리고 정수타입(int)에서 Person 타입으로 명시적 형 변환이 가능하도록 구현하고 Person 타입에서 문자열(string)타입으로 묵시적 형 변환이 가능하도록 오버로딩 해 보겠습니다.
class Person{
public string name;
public int age;
public Person(string name, int age){
this.name = name;
this.age = age;
}
//명시적 형변환 오버로딩
public static explicit operator Person(int age){
return new Person("아무개", age);
}
//묵시적 형변환 오버로딩
public static implicit operator string(Person person){
return "제 이름은 " + person.name + "입니다";
}
}
이렇게 클래스가 정의되고 클래스에서 각각의 형 변환을 위한 오버로딩 메서드가 구현되었으면 다음과 같이 사용할 수 있습니다.
int age = 20;
Person person1 = (Person) age; //명시적 형변환 수행(int -> Person 으로 변환)
Person person2 = new Person("홍길동", 20);
string s = person2; //묵시적 형변환 수행(Person -> string 으로 변환)
참고로 string 형 변환 오버로딩을 구현 한 경우 ToString 메서드도 같이 오버라이딩 해 주는 것이 좋습니다.
이상으로 연산자 오버로딩 강좌를 마치도록 하겠습니다.
행복한 한 주 되세요 ~~~
'SW개발' 카테고리의 다른 글
| [C# 기초강좌] 13. C# 상수 선언, const 와 readonly (43) | 2023.11.06 |
|---|---|
| [C# 기초강좌] 12. C# 인덱서와 프로퍼티 (4) | 2023.11.06 |
| [C# 기초강좌] 11. C# 오버로딩과 오버라이딩 그리고 new (23) | 2023.11.02 |
| [C# 기초강좌] 10. C# 생성자와 소멸자 (0) | 2023.11.02 |
| [C# 기초강좌] 9. C# 배열 (2) | 2023.11.02 |
이 글은 제가 과거에 운영했던 사이트인 http://dotnet.mkexdev.net 의 글을 옮겨온 것입니다. 원본 글은 2010년에 작성되었습니다.
그 전에 운영했었던 사이트(mkex.pe.kr)은 흔적도 없이 사라 졌습니다. 그속의 글들도 모두... 그래서 이 사이트도 사라지기 전에 옮기고 싶은 글을 조금씩 이 블로그로 이동시키려 합니다.
(원본글) http://dotnet.mkexdev.net/Article/Content.aspx?parentCategoryID=1&categoryID=5&ID=677
이 글은 닷넷 기초 지식을 전파하기 위해 2010경에 작성되었으며, 당시 윤성우의 프로그래밍 스터디그룹 네이버 카페에도 필진으로 참여하여 연재했던 글이기도 합니다. 현재 시점에서 조금 달라진 부분이 있을 수 있으나 기본 원리와 언어 기초에 해당하는 부분은 크게 변하지 않았을 것으로 생각하며 이런 부분들을 감안해서 봐 주시기 바랍니다.
“상수 선언, const 와 readonly”
안녕하세요. 박종명입니다. 닷넷 열세 번째 강좌를 진행하도록 하겠습니다.
이번 강좌는 C#에서 상수를 선언하는 키워드인 const 와 readonly 에 대해 알아 보겠습니다.
상수 선언에 있어 왜 두 가지 키워드를 제공해 주는 걸까요?
두 키워드의 설명과 사용법 그리고 차이점에 대해 하나씩 살펴보도록 하겠습니다
‘변하는 수’ 혹은 ‘변경 가능한 수’를 변수라 합니다. 프로그램을 개발할 때 필수로 사용되는 한 요소이죠.
상수는 그 반대 입니다. 상수는 ‘변하지 않는 수’, ‘변경할 수 없는 수’를 말합니다.
영어로 ‘변함없는’ 이라는 뜻을 가진 constant 로 해석되며 한자로는 항상 상(常)자를 이용하여 상수(常數) 라 합니다.
어떤 수를 한번 정의 해 두면 더 이상 변경할 필요가 없는 것을 상수로 선언해 사용하게 되는데요.
대표적으로 이러한 류의 데이터 예로 원주율인 π(파이) 를 들 수 있겠습니다.
private const PI = 3.14;
원주율 값이 정해져 있기 때문에 한번 그 값이 설정되면 프로그램 수행 도중 다른 곳에서 수정할 이유가 없는 것이죠.
따라서 상수로 사용하는 좋은 예입니다
이처럼 변하지 않는 원주율 값을 상수로 선언해 두면 이 값을 참조하기 위해 어느 곳에서든 PI 를 이용할 수 있습니다.
물론 이 경우 상수로 선언하지 않아도 원주율이 필요한 곳에서 3.14 란 값을 직접 사용할 수도 있습니다.
그러나 프로그램의 직관성 및 효율성을 위해 의미 있는 이름의 상수 선언을 권장합니다.
const
영어로 상수란 뜻을 가진 단어인 constant의 표현 그대로가 사용된 대표적인 상수 선언 키워드 입니다.
간단히 아래와 같이 상수 값을 선언할 수 있습니다
class MyClass{
public const int X = 1;
}
const 상수의 하나씩 살펴 보도로 하겠습니다.
const 상수는 반드시 선언 시 그 값을 할당해야 한다
일반적인 멤버 변수는 선언 시 값을 할당하지 않아도 자료형에 따른 기본 값이 자동 할당됩니다.
반면 const 상수는 선언 시 반드시 그 값을 할당(초기화)해야 합니다.
const 상수는 한번 값이 할당되면 이후 변경 불가능하다
당연한 예기죠. 상수니깐요. 당연한 것을 굳이 설명하는 이유는 이후 알아볼 readonly의 차이점 때문입니다.
const 상수는 자동으로 static 이다
const 로 선언한 상수는 자동으로 static 변수가 됩니다. 즉 정적 상수의 역할을 하게 되는 것이죠.
다음과 같이 const 상수와 일반 변수를 선언하고 IL코드를 보면 const 상수는 자동으로 static 키워드가 추가된 것을 확인할 수 있습니다
class MyClass{
public const int X = 1;
public int Y = 1;
}

자동으로 static 이기 때문에 코드에서 명시적으로 static 를 지정할 수 없습니다.
public static const int X = 1; //컴파일 오류 발생
참조 형식 상수 선언
참조 타입은 const 일 수 없습니다. 다만 string 객체는 가능합니다.
엄밀히 말하면 참조 타입이 const일 수 없다기 보다는 const 로 선언된 참조 타입의 값은 null 일수 밖에 없다는 것입니다.
동적으로 메모리에 할당되는 객체와 같은 참조타입을 const 로 선언하여 초기화 할 수 없습니다
예를 들어 다음과 같이 배열(참조타입)을 const로 선언하여 초기화 할 수 없습니다
public const int[] array = new int[] { 1, 2 }; //컴파일 오류 발생
이는 const 상수의 값은 반드시 컴파일 시점에 결정되어야 하는, 다시 말해 컴파일 타임에 완전하게 계산될 수 있는 값이어야 하기 때문입니니다. 컴파일러는 const 상수를 컴파일 시 그 값을 어셈블리의 메타데이터에 바로 기록하도록 합니다.
그러나 한가지 예외가 있는데요. 바로 문자열 객체입니다.
문자열(string) 역시 참조타입 이지만 const 로 선언할 수 있습니다. 문자열은 컴파일 시 그 값을 메타데이터에 정확히 기록할 수 있기 때문에 상수로 사용이 가능합니다
public const string S = "MKEX"; //사용 가능함
더불어 참조 형식을 const 로 선언할 경우 null로 초기화는 가능합니다.
public const MyClass myClass = null; //사용 가능함
그러나 상수는 이후에 변경이 불가능하기 때문에 이러한 코드는 무의미 할 수 있습니다. 따라서 참조타입 상수화는 문자열을 제외하고는 잘 사용하지 않습니다.
const 상수는 참조형태로 전달할 수 없습니다
앞의 내용과 연관되는 부분인데요.
const 상수는 ref 나 out 키워드를 사용하여 참조형태로 값을 전달할 수 없습니다.
앞서 설명한대로 const 상수는 컴파일 시 메타데이터에 그 값이 직접 기록되기 때문에 런타임 시에 이 상수에 대한 메모리 할당은 이루어지지 않습니다. 따라서 주소 값을 기반으로 하는 ref와 같은 참조형태로 값을 전달할 수 없는 것입니다.
상수를 선언하고 그 상수를 사용할 경우 IL 코드를 보겠습니다
다음과 같이 const 상수 X가 10으로 초기화 되어 있고…
class MyClass{
public const int X = 10;
}
이 상수 X를 사용하는 다음 어셈블리의 IL코드를 보면 아래 그림과 같습니다.
class Program {
static void Main(string[] args){
Console.WriteLine(MyClass.X);
}
}

Main 메서드의 메타데이터인데요,
상수 X의 실제 값인 10 이 메타데이터로 바로 기록된 것을 확인할 수 있습니다.
상수 선언에 다른 상수를 사용할 수 있습니다.
다음 코드와 같이 상수를 선언할 때 이미 정의된 다른 상수를 대입하여 상수식을 만들 수 있습니다.
class MyClass{
public const int X = 1;
public const int Y = X * 2;
}
readonly
닷넷은 상수 선언을 위해 const 외에 readonly 라는 키워드도 추가로 제공합니다.
상수면 상수지 왜 두 가지 버전의 상수를 선언하도록 하는 것일까요?
그것은 바로 상수 값의 초기화 방법에 대한 확장을 주기 위함입니다.
앞서 const 는 선언과 동시에 값을 할당, 즉 초기화 해야 한다고 했습니다.
그러나 readonly는 여기에 더불어 생성자에서 한번 더 값을 할당할 수 있는 확장성을 제공합니다.
즉 readonly 상수는 선언할 때 값을 할당할 수도 있으며 생성자에도 할당할 수 있습니다.
다음코드처럼 readonly 상수인 X는 선언 시 초기화 하고 더불어 생성자에서도 그 값을 변경할 수 있습니다.
class MyClass{
public readonly int X = 1;
public MyClass(int i){
X = i; //생성자를 통해 상수 읽기전용 X의 값을 할당한다
}
}
결과적으로 readonly 상수의 값을 생성자에 따라 다르게 구현할 수 있는 확장성이 제공되는 것입니다.
그래서 const 를 컴파일 타임 상수라고 하며 readonly 를 런타임 상수라고 부르기도 합니다.
readonly 상수의 특징을 하나씩 살펴 보도로 하겠습니다.
readonly 상수는 선언 시 값을 할당하지 않아도 됩니다.
const 상수는 선언과 동시에 값을 초기화해야 하지만 readonly 상수는 선언 시 초기화가 의무는 아닙니다.
즉 readonly 상수를 선언할 때 값을 할당하지 않으면 클래스 멤버변수와 같이 타입에 맞는 기본 값이 자동 할당됩니다.
readonly 상수는 생성자에서 한번 더 그 값을 변경할 수 있습니다.
const 는 선언 시 할당된 값은 이후 변경이 불가능한 반면 readonly 상수는 선언 시 값을 초기화 했다고 하더라도 생성자에서 한번 더 그 값을 변경할 수 있습니다. 이것이 const 와의 핵심적인 차이라 하겠습니다.
readonly 상수는 static 이 아닙니다
const 는 자동으로 static 이지만 readonly 는 그렇지 않습니다. const 가 클래스 상수라면 readonly 는 객체 상수라고 할 수 있습니다.
즉 readonly 상수는 클래스의 인스턴스로 생성된 객체를 통해서 접근할 수 있습니다.
아래 IL코드를 보면 readonly 로 선언된 상수 X는 static 아 아님을 알 수 있습니다.

다만 readonly 상수를 정적 상수로 만들고 싶으면 static 키워드를 명시해 주면 됩니다.
만일 readonly 를 static키워드와 같이 사용하여 정적 상수로 만들 경우에는 일반 생성자가 아닌 정적 생성자를 통해서만 값을 변경할 수 있습니다
다음 코드를 보면 X 가 정적 상수로 선언되어 있습니다. 그리고 정적 생성자를 통해 그 값을 한번 더 변경하도록 합니다.
class MyClass{
public static readonly int X = 1;
static MyClass()
{
X = 2; //static로 선언된 readonly상수는 static 생성자를 통해 값을 변경할 수 있다다
}
}
참조 형식 상수 선언
const 에서는 문자열(string)과 null을 제외하고는 참조 타입을 초기화 할 수 없는 반면 readonly는 참조타입의 객체를 생성할 수 있습니다. 즉 다음과 같은 선언이 가능합니다.
public readonly int[] array = new int[] { 1, 2 };
따라서 readonly는 상수라는 표현보다는 읽기전용 필드라고 표현하는 것이 일반적입니다.
한가지 예외, 리플렉션
readonly 로 선언된 읽기전용 필드는 선언 시 한번 그리고 생성자에서 한번 해서 총 두 지점에서만 값의 초기화가 가능하다고 하였습니다.
그러나 리플렉션 기법을 이용하면 실행 중에도 이 값을 변경할 수 있습니다.이것은 예외 적인 상황이라 할 수 있는데요. 사실 리플렉션은 일반적인 클래스 사용 패턴이 아니기 때문에 굳이 예외적이라기 보다는 특수한 형태라는 표현이 더 맞겠네요. 리플렉션에 관해서는 다음 기회에 알아 보도록 하겠습니다.
const 보다는 readonly를 사용하라???
닷넷 개발자들이 자주 하는 말입니다. ‘상수를 사용할 거면 const 보다는 readonly를 사용하라’ 입니다.
이것은 다중 어셈블리환경, 어셈블리 간 참조로 구성된 프로그램일 경우 어셈블리 버전 문제에 해당되는 내용입니다.
만일 A라는 어셈블리에 const 상수가 존재하고 B라는 어셈블리에서 A를 참조해서 상수를 사용하는 경우에 상수 값이 변경되어 A 어셈블리를 다시 컴파일 해서 배포할 경우 B 어셈블리에서는 이 내용이 갱신되지 않는 문제가 발생합니다. 즉 버전 변경에 따른 예기치 않은 결과가 나타나는 것이죠.
이 경우 A 어셈블리뿐만 아니라 이를 참조하는 B 어셈블리도 같이 재 컴파일 해야만 문제를 해결할 수 있습니다.
이것은 앞서 설명한대로 const 상수는 이를 사용하는 어셈블리의 메타데이터로 그 값이 직접 기록되기 때문에 발생하는 문제입니다. 즉 A 어셈블리는 외부어셈블리이지만 B 어셈블리의 메타데이터로 상수 값 자체가 기록되어 버리기 때문에 A 어셈블리의 버전 업이 B어셈블리의 메타데이터를 변경하지는 못하는 것입니다.
만일 A 어셈블리의 상수가 readonly 필드로 정의되어 있다면 이러한 문제로부터 자유로워 집니다.
즉 readonly 필드의 값은 B 어셈블리의 메타데이터에 바로 기록되는 것이 아니라 외부 어셈블리를 참조하도록 기록되기 때문에 A어셈블리의 재 컴파일 만으로도 변경된 값이 적용되는 것입니다.
이런 이유로 해서 ‘const 보다는 readonly를 사용하라’ 라고 하는 것입니다.
만일 이런 상황이 아니라면 굳이 readonly 가 더 좋을 이유는 없습니다.
자세한 내용이 궁금하시면 아래 글을 참고해 보기 바랍니다
http://mkexdev.net/Article/Content.aspx?parentCategoryID=1&categoryID=5&ID=515
그럼 이것으로 강좌를 마치도록 하겠습니다
좋은 하루 되세요~~
'SW개발' 카테고리의 다른 글
| [C# 기초강좌] 14. C# 연산자 오버로딩 (1) | 2023.11.20 |
|---|---|
| [C# 기초강좌] 12. C# 인덱서와 프로퍼티 (4) | 2023.11.06 |
| [C# 기초강좌] 11. C# 오버로딩과 오버라이딩 그리고 new (23) | 2023.11.02 |
| [C# 기초강좌] 10. C# 생성자와 소멸자 (0) | 2023.11.02 |
| [C# 기초강좌] 9. C# 배열 (2) | 2023.11.02 |
이 글은 제가 과거에 운영했던 사이트인 http://dotnet.mkexdev.net 의 글을 옮겨온 것입니다. 원본 글은 2010년에 작성되었습니다.
그 전에 운영했었던 사이트(mkex.pe.kr)은 흔적도 없이 사라 졌습니다. 그속의 글들도 모두... 그래서 이 사이트도 사라지기 전에 옮기고 싶은 글을 조금씩 이 블로그로 이동시키려 합니다.
(원본글) http://dotnet.mkexdev.net/Article/Content.aspx?parentCategoryID=1&categoryID=5&ID=676
이 글은 닷넷 기초 지식을 전파하기 위해 2010경에 작성되었으며, 당시 윤성우의 프로그래밍 스터디그룹 네이버 카페에도 필진으로 참여하여 연재했던 글이기도 합니다. 현재 시점에서 조금 달라진 부분이 있을 수 있으나 기본 원리와 언어 기초에 해당하는 부분은 크게 변하지 않았을 것으로 생각하며 이런 부분들을 감안해서 봐 주시기 바랍니다.
“인덱서(Indexer) 와 프로퍼티(Property) 는 결국 메서드 입니다”
안녕하세요. 박종명입니다. 닷넷 열두 번째 강좌를 진행하도록 하겠습니다.
이번 강좌는 C#의 인덱서와 프로퍼티라는 언어적 특징을 소개 합니다.
인덱서와 프로퍼티는 언어적 편리성을 제공하기 위한 C#의 기능이며 이 둘은 결국 메서드의 조금 다른 표현이라
할 수 있습니다.
C#은 개발자를 위해 많은 언어적 기능을 제공하는데요.
인덱스와 프로퍼티도 이러한 기능의 일부 입니다. 이 둘의 사용형태는 조금 다르지만 많은 유사성이 있습니다.
그리고 사용법이 간단하여 같이 묶어 설명 드리겠습니다. 그럼 하나씩 살펴 보도록 합니다
프로퍼티(Property)
Property 는 ‘사물의 속성’이라는 뜻을 가지고 있습니다. 닷넷에서도 같은 의미로 사용되는데요. msdn에서도 ‘속성’ 이라고 번역하고 있습니다. 우리가 일반 적으로 말하는 클래스의 속성, 즉 멤버 변수에 대한 읽기/쓰기가 가능한 메서드를 ‘프로퍼티(Property)’라고 합니다.
일반적으로 클래스에 변수는 private로 선언합니다.
이는 외부에서 변수를 마음대로 변경하거나 의도하지 않은 액세스를 하지 못하도록 하기 위한 캡슐화 기법입니다.
따라서 이러한 변수에 대한 접근(읽기)과 변경(쓰기)은 별도로 노출하는 공용(public) 메서드를 통해 이루어 지도록 하는데요
흔히 이러한 변수 엑세스 메서드를 갯터(Getter), 셋터(Setter)라고 합니다
닷넷에서는 변수에 대한 갯터,셋터를 따로 만들 필요 없이 프로퍼티라는 것을 통해 하나의 메서드를 통해 정의 가능토록 해 줍니다. 결국 프로퍼티는 클래스 멤버변수의 읽기/쓰기에 대한 겟터/셋터를 표현하는 간소화 하는 일종의 메서드인 셈입니다.
간단한 예를 보겠습니다.
사람을 추상화하는 Person 클래스를 정의하고 나이(age), 이름(name)이라는 멤버 변수를 가지도록 합니다.
다만 이 변수들은 외부에서 직접 접근할 수 없도록 private 로 선언하고 프로퍼티를 통해 이 변수들에 읽기/쓰기가 가능토록 구현합니다. 그리고 프로퍼티 정의를 보면 나이(age)의 경우 그 값의 범위를 제한하고 있으며 이름(name)의 경우 추가 문자열을 붙여서 반환하도록 구현했습니다.
프로퍼티를 통한 이러한 제약을 가함으로써 멤버 변수에 대한 값의 무결성과 안정성을 보장하도록 하는 것입니다.
class Person{
private int age;
private string name;
public int Age{
get { return age; }
set
{
if (age < 1 || age > 200)
throw new ArgumentException("나이가 현실적이지 않습니다");
else
age = value;
}
}
public string Name
{
get { return "제 이름은 " + name + "입니다"; }
set { name = value; }
}
}
프로퍼티의 특징
그럼.. 프로퍼티의 언어적 특징과 유용성에 대해 알아 보겠습니다.
- 프로퍼티는 변수처럼 사용한다
프로퍼티를 정의하면 다음과 같이 사용할 수 있습니다.
Person person = new Person();
person.Name = "홍길동";
person.Age = 20;
Console.WriteLine(person.Name);
마치 클래스의 변수에 조작하는 것과 유사합니다. 즉 일반적인 메서드 호출형태가 아니라 변수 호출 형태를 띄고 있습니다. 그래서 프로퍼티를 논리적인 변수라고도 합니다.
- 그러나 프로퍼티는 변수가 아닙니다
프로퍼티는 변수처럼 사용할 뿐이지 실제로 변수는 아닙니다. 즉 변수와 같은 형태의 메모리 주소를 가지지는 않습니다. 따라서 주소 값을 기반으로 하는 ref, out 키워드와 함께 매개변수로 사용될 수 없습니다.
- 결국 프로퍼티는 메서드 입니다
프로퍼티는 실제로 메서드입니다. 프로퍼티는 클래스 멤버 변수에 대한 갯터,셋터 표현을 간단히 하기 위한 언어적 기능일 뿐이며 컴파일 시 get,set 메서드가 자동으로 만들어 집니다.
아래 IL코드(중간언어)를 보면 프로퍼티로 정의했던 Age와 Name을 위한 각각의 get, set 메서드가 추가된 것을 확인할 수 있습니다.

- 프로퍼티는 void 형이 될 수 없습니다
일반적인 메서드는 반환형식이 void 일 수 있지만 프로퍼티는 void 일 수 없습니다.
일반 변수가 void 형일 수 없기 때문에 변수에 대한 액세스 메서드인 프로퍼티가 void 형이 될 수 없는 것은 어찌 보면 당연한 것입니다
- 그 외엔 메서드와 동일합니다
void 형이 될 수 없는 것을 제외하면 일반적인 메서드의 특성을 그대로 가지고 있습니다. 즉 virtual 선언, abstract 선언, override 재정의 등을 모두 적용할 수 있습니다
- Set 을 위한 value
프로퍼티의 셋터인 set 블록에서는 value 를 통해 값을 얻어 오게 됩니다. value 는 프로퍼티에서 입력 값에 해당하는 암시적 매개변수를 위한 키워드 입니다
public int Age
{
set { age = value; }
}
- 읽기 전용 속성
특정 멤버 변수에 대한 수정은 막고 읽기만 가능하도록 하기 위해 읽기 전용 속성을 만들 수 있습니다. 읽기 전용 속성은 프로퍼티에 set 을 정의하지 않으면 됩니다. 아래 코드는 읽기 전용 나이(age) 속성입니다
public int Age
{
get { return age; }
}
- 서로 다른 접근 제한
하나의 프로퍼티에 get, set 의 접근 제한을 다르게 둘 수 있습니다. 아래 코드는 이름(name)이라는 프로퍼티에 get, set 각각 다른 접근 제한을 둔 예입니다
public string Name
{
get { return name; }
protected set { name = value; }
}
인덱서(Indexer)
인덱서는 객체를 배열처럼 사용할 수 있게 하는 닷넷 언어적 기능입니다. 이 역서 프로퍼티와 같이 메서드의 특수한 표현인데요.
클래스안에 배열이나 컬렉션과 같이 복합 값이 있을 경우 유용하게 사용할 수 있습니다.
다음 예제와 같이 클래스에 배열이 선언되어 있고 이 배열에 대한 접근을 인덱서를 통하도록 구현할 수 있습니다.
class MyClass{
private int[] array = new int[5];
public int this[int i]
{
get
{
return array[i];
}
set
{
array[i] = value;
}
}
}
인덱스는 this 키워드를 통해 구현합니다. 이렇게 정의된 클래스에 대한 객체는 다음과 같이 배열처럼 사용할 수 있게 됩니다
MyClass myClass = new MyClass();
myClass[0] = 100;
Console.WriteLine(myClass[0]);
인덱서의 특징
- 인덱서 역시 메서드 입니다
프로퍼티 처럼 인덱서 역시 결국 메서드입니다. IL 코드를 보면 프로퍼티와 아주 유사하게 get,set 메서드가 자동으로 추가 되어 있음을 확인할 수 있습니다

- 인덱서는 static 일 수 없습니다
프로퍼티는 static 일 수 있지만 인덱스는 불가능 합니다.
인덱스를 생성하는 키워드 자체가 this 입니다. 결국 클래스가 인스턴스화 되었을 때만이 사용가능 해 집니다.
- 인덱서도 void 형이 될 수 없습니다
- 인덱서도 변수가 아니기 때문에 ref, out 와 함께 인자로 사용될 수 없습니다
- 인덱서도 virtual , abstract, override 등이 가능합니다
인덱서의 첨자
인덱스는 객체를 배열처럼 다룰 수 있다고 했습니다.
배열은 첨자를 정수만 사용할 수 있는 반면 인덱서는 첨자가 반드시 정수 타입일 필요는 없습니다
다음 코드는 인덱서의 첨자로 문자열 타입(string)를 사용한 예입니다
class NickName{
private Dictionary<string, string> names = new Dictionary<string, string>();
public string this[string realName]
{
get { return names[realName]; }
set { names[realName] = value; }
}
}
닷넷, 인덱스 예) String 클래스의 인덱서
닷넷이 제공하는 기본적인 라이브러리에 인덱서의 사용 예를 쉽게 찾아 볼 수 있습니다.
대표적으로 string 클래스를 들 수 있습니다.
string s = "mkex";
char c = s[1];// <- 'k' 가 반환된다
String 은 immutable 객체 즉 불변 객체 이기 때문에 읽기전용 인덱스만 제공하고 있습니다.
String 클래스의 인덱스 정의는 대략 아래와 같습니다.
class String{
public char this[int index]{
get {
if(index < 0 || index >= Length)
throw new ArgumentOutOfRangeException();
...
}
}
}
마지막으로 msdn에서 소개하는 인덱서와 프로퍼티의 차이점 표를 제시해 드리며 강좌를 마치도록 하겠습니다.
행복한 한 주 되세요~~
인덱서는 속성과 비슷합니다. 다음표에 나와 있는 차이점을 제외하면 접근자에 정의된 모든 규칙이 인덱서 접근자에도 적용됩니다
| 속성 | 인덱서 |
| 공용 데이터 멤버인 것처럼 메서드를 호출할 수 있습니다. | 개체가 배열인 것처럼 개체에 대한 메서드를 호출할 수 있습니다. |
| 단순한 이름을 통해 액세스할 수 있습니다. | 인덱스를 통해 액세스할 수 있습니다. |
| 정적 또는 인스턴스 멤버가 될 수 있습니다. | 인스턴스 멤버여야 합니다. |
| 속성의 get 접근자에는 매개 변수가 없습니다. | 인덱서의 get 접근자는 인덱서와 동일한 형식 매개 변수 목록을 가집니다. |
| 속성의 set 접근자에는 명시적인 value 매개 변수가 포함됩니다. | 인덱서의 set 접근자는 value 매개 변수 외에도 인덱서와 동일한 형식 매개 변수 목록을 가집니다. |
'SW개발' 카테고리의 다른 글
| [C# 기초강좌] 14. C# 연산자 오버로딩 (1) | 2023.11.20 |
|---|---|
| [C# 기초강좌] 13. C# 상수 선언, const 와 readonly (43) | 2023.11.06 |
| [C# 기초강좌] 11. C# 오버로딩과 오버라이딩 그리고 new (23) | 2023.11.02 |
| [C# 기초강좌] 10. C# 생성자와 소멸자 (0) | 2023.11.02 |
| [C# 기초강좌] 9. C# 배열 (2) | 2023.11.02 |
이 글은 제가 과거에 운영했던 사이트인 http://dotnet.mkexdev.net 의 글을 옮겨온 것입니다. 원본 글은 2010년에 작성되었습니다.
그 전에 운영했었던 사이트(mkex.pe.kr)은 흔적도 없이 사라 졌습니다. 그속의 글들도 모두... 그래서 이 사이트도 사라지기 전에 옮기고 싶은 글을 조금씩 이 블로그로 이동시키려 합니다.
(원본글) http://dotnet.mkexdev.net/Article/Content.aspx?parentCategoryID=1&categoryID=5&ID=675
이 글은 닷넷 기초 지식을 전파하기 위해 2010경에 작성되었으며, 당시 윤성우의 프로그래밍 스터디그룹 네이버 카페에도 필진으로 참여하여 연재했던 글이기도 합니다. 현재 시점에서 조금 달라진 부분이 있을 수 있으나 기본 원리와 언어 기초에 해당하는 부분은 크게 변하지 않았을 것으로 생각하며 이런 부분들을 감안해서 봐 주시기 바랍니다.
“메서드 재정의 3형제: 오버로딩(overloading), 오버라이딩(overriding), 그리고 뉴(new)”
안녕하세요. 박종명입니다. 닷넷 열한 번째 강좌를 진행하도록 하겠습니다.
이번 강좌는 C#에서 메서드 정의 기법인 오버로딩과 오버라이딩 그리고 new 에 대해 알아 보겠습니다.
이 세 가지 기법은 기존에 정의되어 있는 메서드와 동일한 이름으로 추가 및 재 정의하는 기법으로써, 그 필요성과 용례 및 문법적 규칙은 조금씩 다르지만 큰 의미에서 메서드를 재정의 기법이라 할 수 있겠습니다
오버로딩(Overloading)
일반적으로 하나의 클래스 안에 정의된 메서드들의 이름은 중복될 수 없습니다.
그러나 오버로딩 기법을 이용하면 하나의 클래스에 같은 이름을 가진 메서드를 여러 개 정의할 수 있습니다.
다만 메서드의 이름은 같되 매개변수의 정보(개수 및 타입)는 달라야 합니다.
메서드의 이름과 입력 매개변수의 정보(개수 및 타입)를 메서드의 시그너처라고 합니다.
: 메서드 시그너처(Signature): 메서드 이름 + 매개변수 정보(개수 및 타입 정보)
한 클래스에 정의된 메서드들은 모두 시그너처 정보가 유일해야 합니다. 즉 메서드의 시그너처를 유일하게 한다면 메서드의 이름은 얼마든지 같을 수 있는 것입니다. 결국 오버로딩 기법은 이미 정의된 메서드와 이름은 같지만 시그너처는 다르기 때문에 가능한 것입니다
다음 코드는 하나의 클래스의 동일한 이름의 메서드(그러나 시그너처는 다른)가 정의된 모습입니다.
public class MyClass{
public int MyMethod(){
return 0;
}
public int MyMethod(int i){
return i;
}
}
오버로딩은 왜 사용하나?
오버로딩 기법을 사용하지 않고도 프로그램을 완성할 수 있습니다.
오버로딩이 유용한 경우는 경험에 의해 그리고 감각적으로 알 수 있어 여러 사례가 있겠습니다만, 저는 이런 경우를 생각해 보았습니다
동일하거나 유사한 일을 수행하는 메서드가, 전달 받는 매개변수에 따라 조금씩 다른 연산을 해야 하는 경우에 모든 상황에 따라 메서드 이름을 각각 정의 하는 것보다 매개변수 정보만 달리하여 동일한 이름으로 정의한다면 코드를 작성하는 입장에서나 사용하는 입장에서 모두 보다 직관적이고 편리하게 사용할 수 있을 것입니다.
닷넷 프레임워크의 라이브러리에서도 이러한 필요성에 의한 메서드 오버로딩 예를 쉽게 찾아 볼 수 있습니다.
예를 들어 FileInfo 클래스에 Open 메서드는 다음과 같이 3개로 오버로딩 되어 있습니다
- FileInfo.Open(FileMode)
- FileInfo.Open(FileMode, FileAccess)
- FileInfo.Open(FileMode, FileAccess, FileShare)
즉 파일 열기를 할 때 모드만 지정하거나 읽기/쓰기 권한을 같이 지정하거나 공유 권한을 모두 지정할 수 있도록 하는 것입니다. 만일 FileMode만 지정한다면 나머지 값들은 미리 정의된 기본 값으로 지정됩니다.
대체로 이 기본 값은 일반적으로 가장 많이 쓰이는 값이기 때문에 개발자는 모든 상황을 고려할 필요 없이 필요한 정보만 전달하면 되는 것입니다.
물론 상세한 설정을 원하면 얼마든지 가능하구요.
마치 프로그램 설치 시 기본 설정과 상세(사용자 정의) 설정이 있는 것과 유사해 보입니다.
메서드 오버로딩이 지원되지 않는다면 아마도 아래와 같이 메서드 이름을 각기 달리하여 구현해야 할 것입니다.
아래는 제가 임의로 명명한 예입니다
- FileInfo.Open(FileMode)
- FileInfo.OpenWithFileAccess(FileMode, FileAccess)
- FileInfo.OpenWithFileAccessAndFileShare(FileMode, FileAccess, FileShare)
매개변수가 더 많을 경우에는 더 복잡해 지겠죠.
아래의 예는 큰 수를 반환하는 메서드를 전달받는 매개변수의 수에 따라 오버로딩 한 예시입니다.
public class MyClass{
public static int Max(int i, int j){
return i > j ? i : j; //둘 중 큰수를 반환한다
}
public static int Max(int i, int j, int k){
return Max(Max(i, j), k); //Max(int, int) 를 호출한다
}
public static int Max(int i, int j, int k, int l){
return Max(Max(i, j, k), l); //Max(int, int, int) 를 호출한다
}
public static int Max(int[] arrays){
int maxValue = 0;
foreach (int i in arrays){
maxValue = Max(maxValue, i); //Max(int,int) 를 호출한다
}
return maxValue;
}
}
오버라이딩(Overriding)
앞서 살펴본 오버로딩(Overloading)은 한 클래스 내에서 동일한 이름의 메서드를 추가 정의하는 것인 반면, 오버라이딩(Overriding)은 클래스간 상속 관계에서 메서드를 재 정의하는 기법입니다
두 클래스가 상속 관계에 있으면 부모 클래스의 public, protected 으로 선언된 메서드는 자식 클래스로 그대로 상속되어 자식클래스에서 사용이 가능하게 됩니다. 즉 이미 정의된 메서드를 재 사용하게 되는 것이죠.
이 때 단순히 재 사용을 하지 않고 자식 클래스에서 상속 받은 메서드를 재 정의하여 다른 연산을 수행하도록 하는 것이 오버라이딩 입니다. 즉 자식 클래스에서 부모 클래스의 특정 메서드를 다시 정의하게 됩니다.
오버라이딩은 오버로딩과는 달리 메서드의 이름이 동일해야 합니다.
그리고 virtual 과 override 키워드를 사용하여 오버라이딩을 구현하게 됩니다.
virtual 과 override 키워드
메서드를 오버라이딩 할 때 부모 클래스에서는 virtual 로 자식 클래스에서는 override 키워드로 메서드를 정의해야 합니다. 즉 부모 클래스에서는 자식 클래스에서 오버라이딩이 가능하도록 가상(virtual) 메서드로 정의해야 하고 자식 클래스에서는 이 가상메서드를 override 키워드로 재정의 하게 됩니다
다음과 같이 Parent 클래스를 상속받는 Child 클래스가 있을 경우, public 메서드는 자동으로 상속 됩니다.
class Parent{
public virtual void ParentMethod(){
Console.WriteLine("부모 메서드");
}
}
class Child : Parent{}
Child 클래스에는 ParentMethod 가 정의되어 있지 않지만 부모로부터 상속받아서 사용 가능하죠.
Child child = new Child();
child.ParentMethod(); //"부모메서드" 가 출력 됨
이때 부모 클래스의 ParentMethod를 자식 클래스에서는 다르게 구현 하고 싶을 경우 오버라이딩 하면 됩니다.
class Child : Parent{
public override void ParentMethod(){
Console.WriteLine("자식메서드(오버라이드 됨)");
}
}
오버라이딩 된 상태에서 자식 객체로 해당 메서드를 호출하면 재 정의한 메서드가 호출되는 것입니다.
Child child = new Child();
child.ParentMethod();//"자식메서드" 가 출력 됨
자바와는 달리 부모 클래스에서 virtual로 선언하지 않으면 오버라이딩을 할 수 없다는 것에 주의하세요.
(자바는 모든 메서드가 기본적으로 virtual 이죠?)
참고로 virtual 이외에 abstract (추상 메서드) 로 정의되어 있는 메서드 역시 오버라이딩 가능합니다.
오버라이딩의 핵심은 다형성(Polymorphism)
객체 지향의 중요한 개념 중에 하나가 바로 다형성 입니다.
다형성은 같은 메시지에 다른 동작이 가능하게 하는 객체 지향의 특성인데요.
이러한 다형적인 동작을 가능토록 구현하기 위해 오버라이딩 기법을 사용하게 됩니다.
예를 하나 들어 보죠
전 국민의 게임인 스타크래프트(StarCraft)를 개발한다고 가정해 봅니다.
게임에는 많은 유닛이 존재하고 이 유닛들의 공격 형태를 서로 다릅니다.
예를 들어 무대포 질럿은 양 팔에 달린 칼로 공격하고 우직한 드래곤은 꽁알탄 같은 총알을 쏘면서 공격합니다.
이외 다른 유닛들도 공격의 형태가 조금씩 다릅니다.
그리고 공격을 할 때 개별 유닛에게 명령을 내릴 수도 있지만 전체를 모아서 한 번에 공격 명령을 내릴 수도 있습니다. 즉 마우스로 쭈~욱 끌어서 많은 유닛을 선택해서 공격하는 것입니다, 물론 이 때 선택된 유닛들은 공격형태가 서로 다른 것끼리 짬뽕되어 있습니다
이 경우 부모 클래스에 Attack 라는 메서드를 정의 하고 각 유닛 클래스에서는 이 메서드를 오버라이딩 하여 같은 명령에 서로 다른 동작을 하도록 구현하고 싶습니다.
즉 모든 유닛에 한번의 Attack 명령으로 다형적인 동작이 가능토록 하는 것입니다. 코드를 보겠습니다
abstract class Unit //모든 유닛이 상속받게 되는 부모 클래스
{
public abstract void Attack();
}
class Zelot : Unit{
public override void Attack(){
Console.WriteLine("사시미 찔러 대기");
}
}
class Dragon : Unit{
public override void Attack(){
Console.WriteLine("꽁알탄 쏘아 대기");
}
}
이렇게 클래스를 구현하고 이제 공격 명령을 내려 보도록 하겠습니다.
질럿 두 마리와 드래곤 한 마리가 선택되었다고 가정하고 한번에 공격 명령을 내립니다.
static void Main(string[] args){
//그룹 공격(질럿 두마리, 드래곤 한 마리)
Unit[] unitArray = new Unit[] { new Zelot(), new Zelot(), new Dragon() };
foreach (Unit unit in unitArray){
//모든 유닛에 Attack라는 같은 메시지를 호출하여 다른 행위를 하도록 한다
unit.Attack();
}
}
그리고 결과는 다음과 같습니다

모든 유닛에 Attack라는 동일한 메서드를 호출하지만 각 유닛의 공격 행동은 서로 다릅니다.
이렇듯 오버라이딩은 객체의 다형적인 동작을 가능토록 하는 객체 지향 기법입니다.
물론 오버라이딩을 다형성만을 위해서 사용하지는 않습니다.
어떤 경우든 부모 클래스의 virtual 메서드를 재 정의 하고 싶을 경우 사용하면 되는 것입니다.
참고로 오버라이딩은 많은 객체 지향 디자인 패턴에 단골로 사용되는 기법이라 하겠습니다.
대부분의 디자인패턴에서 오버라이딩의 사례를 쉽게 찾아 볼 수 있는 만큼 중요하고도 실용적인 기법이니 개념을 정확히 알고 있으시길 바랍니다.
new
마지막으로 new 를 통한 메서드 재 정의 하는 것을 알아 보겠습니다.
new 역시 오버라이딩처럼 상속과 연관이 있습니다.
다만 new 를 통해 메서드를 재 정의하게 되면 부모 클래스의 원 메서드는 숨기게(가려지게) 되는 차이가 있습니다.
말 그대로 메서드를 새로(new) 정의하는 기법입니다. 부모 클래스의 메서드를 사용하지 않고 새로 정의하는 것이죠.
코드를 보겠습니다
public class Parent{
public void ParentMethod(){
Console.WriteLine("부모 메서드");
}
}
public class Child : Parent{
public new void ParentMethod(){
Console.WriteLine("자식메서드(새로 정의됨)");
}
}
new 는 부모 메서드가 virtual 이거나 아니거나 상관이 없습니다.
new 와 오버라이딩의 차이점
언뜻 보면 오버라이딩과 별반 달라 보이지 않습니다. 그러나 이 둘은 엄연히 다른 기법입니다.
오버라이딩과는 달리 new 를 통한 메서드 재정의는 다형성과 아무런 연관이 없습니다.
C#에서 상속 관계인 두 클래스에서 상위 타입으로의 형 변환은 묵시적으로 이루어 지기 때문에 다음과 같은 코드 작성이 가능합니다
Parent myObject = new Child();
myObject.ParentMethod();
이 때 출력 결과는 어떻게 될까요?
오버라이딩을 했을 경우에는 자식 클래스(Child)의 오버라이드 된 메서드가 실행되는 반면, new 로 재정의 할 경우에는 부모 클래스(Parent)의 원 메서드가 실행됩니다.
new 는 다형성과는 아무런 연관이 없이 단순히 자식 클래스에서 새로이 정의한다는 것입니다.
다시 말해 오버라이딩은 부모 타입으로 메서드를 호출하더라도 객체로 생성된 자식 타입의 메서드가 호출되도록 하여 객체의 다형성이 가능해 지는 것입니다.
이것으로 메서드 재 정의 3형제에 대한 소개를 마치도록 하겠습니다.
오버라이딩과 오버로딩은 실무에서 굉장히 많이 사용되는 기법입니다.
수 많은 코드에서 관련 예를 쉽게 찾아 볼 수 있을 것입니다. 그런 만큼 정확한 개념을 숙지하시기를 바랍니다.
그럼.. 즐거운 주말 되세요~~
'SW개발' 카테고리의 다른 글
| [C# 기초강좌] 13. C# 상수 선언, const 와 readonly (43) | 2023.11.06 |
|---|---|
| [C# 기초강좌] 12. C# 인덱서와 프로퍼티 (4) | 2023.11.06 |
| [C# 기초강좌] 10. C# 생성자와 소멸자 (0) | 2023.11.02 |
| [C# 기초강좌] 9. C# 배열 (2) | 2023.11.02 |
| [C# 기초강좌] 8. C# 제어문(조건문과 반복문) (0) | 2023.11.02 |
이 글은 제가 과거에 운영했던 사이트인 http://dotnet.mkexdev.net 의 글을 옮겨온 것입니다. 원본 글은 2010년에 작성되었습니다.
그 전에 운영했었던 사이트(mkex.pe.kr)은 흔적도 없이 사라 졌습니다. 그속의 글들도 모두... 그래서 이 사이트도 사라지기 전에 옮기고 싶은 글을 조금씩 이 블로그로 이동시키려 합니다.
(원본글) http://dotnet.mkexdev.net/Article/Content.aspx?parentCategoryID=1&categoryID=5&ID=674
이 글은 닷넷 기초 지식을 전파하기 위해 2010경에 작성되었으며, 당시 윤성우의 프로그래밍 스터디그룹 네이버 카페에도 필진으로 참여하여 연재했던 글이기도 합니다. 현재 시점에서 조금 달라진 부분이 있을 수 있으나 기본 원리와 언어 기초에 해당하는 부분은 크게 변하지 않았을 것으로 생각하며 이런 부분들을 감안해서 봐 주시기 바랍니다.
“생성자와 소멸자”
안녕하세요. 박종명입니다. 닷넷 열 번째 강좌를 진행하도록 하겠습니다.
이번 강좌는 C# 의 생성자와 소멸자에 대해 알아보겠습니다.
생성자는 객체가 처음 생성될 때 실행되며 소멸자는 객체가 메모리에서 제거 될 때 실행됩니다
닷넷은 객체의 생성과 소멸 과정에 자동으로 호출되는 두 메커니즘을 제공합니다.
바로 생성자와 소멸자 입니다
생성자
생성자는 객체가 new 키워드로 처음 생성될 때 자동으로 호출되는 일종의 메서드입니다.
객체가 생성될 때 실행되기 때문에 일반적으로 객체의 초기화 작업을 할 때 생성자를 많이 이용합니다.
가장 간단한 생성자 예를 보겠습니다
class MyClass{
public MyClass(){
Console.WriteLine("생성자가 호출되었습니다");
}
}
이렇게 생성자가 정의되어 있으면 다음과 같이 객체를 생성할 때 생성자는 자동으로 호출됩니다
MyClass myClass = new MyClass(); //객체가 생성되면서 생성자가 호출된다
생성자의 기본적인 언어적 규칙 다음과 같습니다
- 생성자는 클래스 이름과 동일해야 한다
- 생성자에는 반환 타입을 정의하지 않는다
- 생성자를 (매개변수를 달리 하여) 여러 개 정의할 수 있다(일반적인 메서드 오버로딩이 적용된다)
- 생성자를 정의하지 않으면 기본 생성자(매개변수 없는 생성자)가 자동으로 추가된다
- 생성자는 상속되지 않는다
생성자 오버로딩
생성자도 일종의 메서드이기 때문에 메서드의 오버로딩 규칙이 적용됩니다.
아래와 같이 매개변수 타입을 달리 하여 여러 개의 생성자를 정의할 수 있습니다.
class MyClass{
public MyClass(){
Console.WriteLine("기본생성자");
}
public MyClass(int i){
Console.WriteLine("int 매개변수 생성자");
}
public MyClass(string s){
Console.WriteLine("string 매개변수 생성자");
}
}
그리고 다음과 같이 객체를 생성할 때 각각의 생성자가 호출되도록 지정할 수 있습니다.
MyClass myClass1 = new MyClass(); //기본생성자 호출
MyClass myClass2 = new MyClass(1); //int 매개변수 생성자호출
MyClass myClass3 = new MyClass("hi"); //string 매개변수 생성자
생성자 호출 체인(this 키워드)
이렇게 하나의 클래스에 여러 개의 생성자가 있을 경우 this 키워드를 이용하여 생성자끼리 호출할 수 있습니다.
즉 생성자끼리 호출 체인(chain)을 형성할 수 있습니다
class MyClass{
//이 생성자가 호출될 때, int매개변수 생성자가 먼저 호출되도록 한다
public MyClass() : this(1){
Console.WriteLine("기본생성자");
}
public MyClass(int i){
Console.WriteLine("int 매개변수 생성자");
}
}
상속과 생성자
생성자는 상속되지 않습니다.
따라서 생성자에 virtual, new, override, sealed 와 같은 상속과 관련된 키워드를 사용할 수 없습니다.
그리고 상속 구조에서의 자식 객체를 생성하면 부모 객체의 생성자부터 시작하여 아래 방향으로 생성자가 모두 호출됩니다. (부모 객체의 기본 생성자가 자동으로 호출됩니다)
class Parent{
public Parent(){
Console.WriteLine("부모생성자");
}
}
class Child : Parent{
public Child(){
Console.WriteLine("자식생성자");
}
}
위와 같이 상속구조로 클래스가 정의된 상태에서 자식 객체를 생성하면(new Child()), 부모 생성자 호출 -> 자식 생성자 호출 순서로 실행됩니다
사실 닷넷의 모든 객체는 System.Object 클래스로부터 상속되므로 실제 순서는 다음과 같습니다

상속간 생성자 호출 체인(base 키워드)
base 키워드를 이용하여 자식 객체의 생성자에서 부모 객체의 생성자를 명시적으로 호출할 수 있습니다.
아래 코드는 자식 객체 생성자에서 부모 객체 특정 생성자를 명시적으로 호출하는 예 입니다.
class Child : Parent{
public Child() : base(1){
Console.WriteLine("자식생성자");
}
}
구조체에서의 생성자
구조체에서도 생성자 정의가 가능합니다.
다만 매개 변수가 없는 생성자를 명시적으로 정의할 수 없으며 적어도 하나 이상의 매개변수를 가진 생성자에 한해 정의가 가능합니다
struct MyStruct{
public MyStruct(int i){
Console.WriteLine("구조체 생성자");
}
}
생성자 사용 사례
생성자에 대한 기본적인 사항들을 살펴 보았는데요.
앞서 언급한대로 일반적으로 생성자는 객체의 초기화 작업에 많이 이용됩니다.
그리고 간혹 객체의 생성 제한을 위해서도 사용되는데요. 간단히 그 예를 들어 보겠습니다.
생성자 사용 형태 1) 객체의 초기화 작업 수행
객체는 상태와 행위를 가지는 현실 세계의 구조를 지향하는 자료구조입니다
객체가 가지는 상태는 객체의 속성으로 정의됩니다.
이러한 객체의 상태를 초기화 하는 용도로 생성자를 사용하게 됩니다.
아래 코드는 사람을 추상화 한 Person 클래스에 나이(age)와 이름(name) 라는 객체의 상태를 초기화 하는데 생성자를 이용한 예입니다
class Person{
int age; string name;
public Person(){
this.age = 0;
this.name = string.Empty;
}
public Person(int age, string name){ //외부에서 전달된 값으로 초기화 수행
this.age = age;
this.name = name;
}
}
생성자 사용 형태 2) 객체의 생성 제한
일반적으로 클래스가 정의되면 이 것을 마음껏 객체로 생성해서 사용하기를 원합니다.
그러나 간혹 외부에서 객체 생성 하지 못하도록 해야 할 경우도 있습니다.
대표적으로 객체를 단 하나만 생성하도록 하는 싱글턴(Singleton) 패턴을 들 수 있습니다.
생성자를 private 로 선언하면 접근 제한에 걸려 외부에서 객체를 생성할 할 수 없게 됩니다.
싱글턴 패턴에서는 객체가 단 하나만 생성됨을 보장해 주는 디자인 패턴인데요.
대략 아래와 같이 구현 가능합니다.
class MyClass{
static MyClass instance;
private MyClass() {} //외부에서 객체를 생성하지 못하도록 private 으로 정의
public static MyClass GetInstance() //객체를 대신 생성해 주는 메서드
{
if (instance == null){
instance = new MyClass();
}
return instance;
}
}
생성자를 private 로 정의하여 외부에서 객체를 생성하지 못하도록 하고 클래스 내부에서 자신의 객체를 반환하는 구조입니다.
참고로 위 코드는 다중 쓰레드 환경에서 안전하지 않습니다.
소멸자
소멸자는 생성자와 정 반대되는 개념입니다
생성자가 객체가 처음 생성될 때 실행되는 메서드라면 소멸자는 객체가 메모리에서 해제 될 때 호출되는 메서드 입니다. 객체가 소멸할 때 처리해야 하는 마무리 작업에 관련된 코드가 기술되는 영역입니다
참고로 닷넷 환경에서는 객체를 프로그래머가 명시적으로 해제하지는 못합니다.
GC라고 명명하는 가비지수집기에 의해 객체는 완전히 소멸되는데 이 GC가 객체를 소멸할 때 호출되는 종료 메서드가 바로 소멸자 입니다.
객체가 소멸될 때 그 객체의 Finalize 메서드가 호출되는데요. 닷넷에서는 소멸자를 정의하면 컴파일러가 자동으로 소멸자코드를 Finalize 코드로 변환해 줍니다
다음과 같이 클래스에 소멸자를 정의하면,
class MyClass{
~ MyClass { //객체가 소멸될 때 수행하게 될 일련의 해제 과정을 기술함 }
}
컴파일 시 암시적으로 다음과 같이 Finalize 메서드로 변환됩니다
protected override void Finalize(){
try{
일련의 해제 과정을 기술함 .
}
finally{
base.Finalize();
}
}
보통 소멸자는 가비지수집기에 의해 메모리 정리가 되지 않는 비관리 리소스(DBConnection, Stream 등)를 명시적으로 해제하는데 이용하게 됩니다. 사실 가비지수집과 ‘관리되는 리소스/비관리 리소스’에 관한 주제는 사실 중요하고도 방대할 수 있습니다. 관련 자료를 참고하시길 바랍니다.
소멸자의 기본적인 언어적 규칙 다음과 같습니다.
- 하나의 클래스에는 단 하나의 소멸자만 정의 가능하다
- 소멸자는 상속되지 않는다
- 소멸자는 개발자의 코드를 통해 명시적으로 호출되지 않는다. GC에 의해 자동 호출 된다
- 소멸자는 ‘~ 클래스 명’ 형태로 접근제한자와 매개변수를 가지지 않는다
- 소멸자는 컴파일러에 의해 자동으로 Finalize 메서드로 대체된다
- 구조체에서는 소멸자를 정의할 수 없다
상속과 소멸자 호출 순서
앞서 살펴본 대로 생성자의 경우 상속 관계에 있을 때 부모 객체 생성자부터 자식객체 생성자로의 호출 순서를 가집니다. 그러나 소멸자는 그 반대입니다
즉 상속관계에 있는 객체가 소멸될 때 자식 객체의 소멸자부터 먼저 호출됩니다.
즉 다음과 같이 코드가 정의되었을 경우 자식 객체(Child)가 소멸될 때 자식 소멸자 호출 -> 부모 소멸자 호출 순서로 실행됩니다
class Parent{
~Parent(){
Console.WriteLine("부모 소멸자");
}
}
class Child : Parent{
~Child(){
Console.WriteLine("자식 소멸자");
}
}

그럼. 이것으로 강좌를 마무리 하겠습니다
즐거운 한 주 되세요~~
'SW개발' 카테고리의 다른 글
| [C# 기초강좌] 12. C# 인덱서와 프로퍼티 (4) | 2023.11.06 |
|---|---|
| [C# 기초강좌] 11. C# 오버로딩과 오버라이딩 그리고 new (23) | 2023.11.02 |
| [C# 기초강좌] 9. C# 배열 (2) | 2023.11.02 |
| [C# 기초강좌] 8. C# 제어문(조건문과 반복문) (0) | 2023.11.02 |
| [C# 기초강좌] 7. 박싱과 언박싱 (6) | 2023.11.02 |
이 글은 제가 과거에 운영했던 사이트인 http://dotnet.mkexdev.net 의 글을 옮겨온 것입니다. 원본 글은 2010년에 작성되었습니다.
그 전에 운영했었던 사이트(mkex.pe.kr)은 흔적도 없이 사라 졌습니다. 그속의 글들도 모두... 그래서 이 사이트도 사라지기 전에 옮기고 싶은 글을 조금씩 이 블로그로 이동시키려 합니다.
(원본글) http://dotnet.mkexdev.net/Article/Content.aspx?parentCategoryID=1&categoryID=5&ID=673
이 글은 닷넷 기초 지식을 전파하기 위해 2010경에 작성되었으며, 당시 윤성우의 프로그래밍 스터디그룹 네이버 카페에도 필진으로 참여하여 연재했던 글이기도 합니다. 현재 시점에서 조금 달라진 부분이 있을 수 있으나 기본 원리와 언어 기초에 해당하는 부분은 크게 변하지 않았을 것으로 생각하며 이런 부분들을 감안해서 봐 주시기 바랍니다.
“1차원, 2차원, 가변 배열 = [] , [,] , [][]”
안녕하세요. 박종명입니다. 닷넷 아홉 번째 강좌를 진행하도록 하겠습니다
이번 강좌는 C# 의 배열에 대해 알아보겠습니다.
배열은 1차원 배열과 2차원 이상의 다차원 배열 그리고 가변배열이 있습니다.
배열은 동일한 타입의 자료를 묶음으로 처리할 때 유용한 자료구조 입니다. 메모리 구조상 배열은 인접한 공간에 순차적으로 저장되지만 우리의 머리 속에서는 행과 열이 있는 행렬로 인식하면 편리합니다.
배열에는 차원이 있는데요. 차원이 하나인 1차원과 2차원 이상의 다차원 배열이 있습니다.
그리고 배열의 요소로 또 다른 배열을 저장할 수 있는 가변배열도 지원됩니다. 지금부터 차례대로 알아 보겠습니다
1차원 배열 ([])
1차원 배열은 차원이 단 한 개로 일정한 수의 항목이 순차적으로 저장되는 구조입니다
1차원 배열을 굳이 행렬로 바라볼 필요는 없지만 굳이 행렬의 구조를 생각한다면
1차원 배열은 행은 오직 1개 이며 열의 크기가 중요합니다.
아래 그림은 1차원 배열에 값이 총 3개(1,2,3)이 저장된 모습입니다(1행 3열이라고 생각해도 무방합니다)

위와 같은 1차원 배열을 생성하기 위해서는 아래 코드 중 하나를 사용할 수 있습니다
방법1) int[] array1 = new int[3];
array1[0] = 1; array1[1] = 2; array1[2] = 3;
방법2) int[] array2 = new int[] { 1, 2, 3 };
방법3) int[] array3 = {1,2,3 };
다차원 배열 ([,])
차원이 2개 이상이면 다차원 배열이라 합니다.
일반적으로 2차원배열을 넘어서는 3차원 이상 배열은 잘 사용하지 않습니다.
2차원 배열은 그야말로 딱 행렬의 구조입니다.
그러나 3차원 배열은 행렬의 행렬 즉 큐브 형태를 떠올려야 합니다. 4차원 배열은요?? 머리 아픕니다 --;
개인적으로 3차원 이상의 배열은 꼭 필요한 경우를 제외하고 웬만해선 사용하지 않기를 바랍니다.
아래 그림은 2차원 배열에 값이 총 6개 저장된 모습입니다(2행 3열의 행렬구조 입니다)

위와 같은 2차원 배열을 생성하기 위해서는 아래 코드 중 하나를 사용할 수 있습니다
방법1) int[,] array1 = new int[2, 3];
array1[0,0] = 1; array1[0,1] = 2; array1[0,2] = 3;
array1[1,0] = 4; array1[1,1] = 5; array1[1,2] = 6;
방법2) int[,] array2 = new int[,] { { 1, 2, 3 }, { 4, 5, 6 } };
방법3) int[,] array3 = { { 1, 2, 3 }, { 4, 5, 6 } };
3차원 이상의 배열은 사용하지 않기를 권장하지만 필요한 경우가 있을 수도 있습니다
간단히 알아 봅니다. 3차원 배열은 행렬의 행렬 구조 즉 큐브와 같은 형태를 떠올려야 합니다.
사실 이렇게 떠올려야 하는 자체가 피곤합니다 --; 그래서 사용하지 않았으면 한답니다 ㅎㅎ
(2,2,3) 인 3차원 배열을 생성해 보겠습니다
int[, ,] array =
new int[,,] { { { 1, 2, 3 }, { 4, 5, 6 } }, { { 7, 8, 9 }, { 10, 11, 12 } } };
다차원 배열의 차수를 계산하기 위해서는 중괄호의 개수와 꼼마(,)를 보면 됩니다
양 끝 중괄호는 무시하고 그 다음 중괄호의 개수와 그리고 그 다음 중괄호 개수
그리고 최종적으로 숫자를 꼼마(,)로 나열한 개수가 차원이 됩니다. 즉 위 코드에서는 2, 2, 3 의 차수를 가지게 됩니다
이는 2차원 이상 다차원 배열에 공히 적용되는 계산법입니다
아래 그림을 참고하세요

다차원배열의 모든 요소를 순회하기 위해서는 각 차원의 수를 계산하여 중첩루프를 돌려야 합니다
아래는 앞서 정의한 3차원 배열의 모든 요소를 순회하는 코드 입니다
for (int i = 0; i < array.GetLength(0); i++) //1차원 수(2개)
{
for (int j = 0; j < array.GetLength(1); j++) //2차원 수(2개)
{
for (int z = 0; z < array.GetLength(2); z++) //3차원 수(3개)
{
Console.Write( array[i, j, z]);
}
}
}
이전 강의에서 말씀 드렸듯이 다차원 배열의 모든 요소를 순회하기 위해 for 루프 대신 foreach 루프를 사용하면
보다 편리하게 순회할 수 있습니다. 아래 코드는 위의 for 루프와 동일한 결과를 가져다 줍니다
foreach (int value in array){
Console.Write(value);
}
가변 배열 ([][])
지금까지 살펴본 1차원, 다차원 배열은 각 차원의 크기가 고정되지만 가변배열을 이용하면 다양한 차원과 크기를
가지도록 구조화 할 수 있습니다
가변배열의 각 요소에는 또 다른 배열이 저장되는데요. 이 때 저장되는 배열의 크기는 서로 다른 크기를 가질 수 있습니다. 따라서 가변배열은 하나의 배열에 다양한 크기를 가진 듯 한 효과를 줄 수 있으며 요소로 배열을 저장하기 때문에 ‘배열의 배열’이라고도 합니다
아래 코드는 2개의 요소를 가진 1차원 가변배열을 생성하는 코드입니다
int[][] array = new int[2][];
array[0] = new int[] { 1, 2, 3 };
array[1] = new int[] { 1, 2, 3, 4 };
배열 0번째 요소는 크기가 3인 1차원 배열을 저장하며 1번째 요소는 크기가 4인 1차원 배열을 저장합니다
사실 저장한다기 보다는 ‘가리킨다’는 표현이 맞겠네요. 아래 그림을 참고하세요

이렇게 생성된 가변배열을 순회하려면 다음과 같이 작성할 수 있습니다
for (int i = 0; i < array.Length; i++){
for (int j = 0; j < array[i].Length; j++){
Console.Write("{0} ", array[i][j]);
}
Console.WriteLine();
}
주의할 점은 가변배열과 다차원 배열은 엄연히 다른 자료구조입니다.
그 표현법도 [,] (다차원 배열) , [][] 가변배열로 서로 상이합니다
배열의 기본 성질 및 추가 내용
- 숫자 타입의 배열 요소에는 기본 값으로 0이 저장됩니다.
단 가변배열을 포함하여 배열의 요소가 참조타입일 경우에는 null 이 기본 값으로 설정됩니다
- 모든 배열은 참조형식 입니다
배열의 요소가 값 형식이라 할 지라도 배열 자체는 참조형식 입니다
- 배열 표기법: int[] array (O), int array[] (X), int[3] array (X)
- 모든 배열은 System.Array 클래스로부터 파생됩니다
배열을 정의하면 컴파일러에 의해 자동으로 Array 클래스로부터 파생되도록 구현됩니다
따라서 Array 클래스에 정의된 배열을 조작하는 다양한 멤버들을 이용할 수 있습니다
System.Array 클래스이 유용한 멤버
모든 배열은 Array 클래스로부터 파생됩니다. 배열의 조작에 있어 Array 클래스에 정의된 유용한 멤버
몇 가지 살펴 봅니다
1) Rank 속성: 배열의 차원 반환
2) Length: 배열의 총 요소 수 반환
3) GetLength(int dimension): dimension에 지정된 차원의 요소 수 반환
4) Clone, CopyTo: 배열 복사
5) Array.Sort(Array): 1차원 배열의 정렬(퀵 정렬)
6) Array.Clear(Array,int,int): 배열 요소 값 지우기(초기화 시킴)
7) Array.IndexOf(Array,obejct): 배열에서 특정 요소 검색(일치하는 값의 인덱스 반환)
8) Array.BinarySearch(Array,object): 정렬된 배열에서 이진탐색 수행
System.Array 클래스에는 이 이외에도 많은 기능이 정의되어 있습니다.
필요 시 msdn을 참고바랍니다
좋은 한 주 되세요~~~
'SW개발' 카테고리의 다른 글
| [C# 기초강좌] 11. C# 오버로딩과 오버라이딩 그리고 new (23) | 2023.11.02 |
|---|---|
| [C# 기초강좌] 10. C# 생성자와 소멸자 (0) | 2023.11.02 |
| [C# 기초강좌] 8. C# 제어문(조건문과 반복문) (0) | 2023.11.02 |
| [C# 기초강좌] 7. 박싱과 언박싱 (6) | 2023.11.02 |
| [C# 기초강좌] 6. C# 자료형 (1) | 2023.11.01 |
이 글은 제가 과거에 운영했던 사이트인 http://dotnet.mkexdev.net 의 글을 옮겨온 것입니다. 원본 글은 2010년에 작성되었습니다.
그 전에 운영했었던 사이트(mkex.pe.kr)은 흔적도 없이 사라 졌습니다. 그속의 글들도 모두... 그래서 이 사이트도 사라지기 전에 옮기고 싶은 글을 조금씩 이 블로그로 이동시키려 합니다.
(원본글) http://dotnet.mkexdev.net/Article/Content.aspx?parentCategoryID=1&categoryID=5&ID=672
이 글은 닷넷 기초 지식을 전파하기 위해 2010경에 작성되었으며, 당시 윤성우의 프로그래밍 스터디그룹 네이버 카페에도 필진으로 참여하여 연재했던 글이기도 합니다. 현재 시점에서 조금 달라진 부분이 있을 수 있으나 기본 원리와 언어 기초에 해당하는 부분은 크게 변하지 않았을 것으로 생각하며 이런 부분들을 감안해서 봐 주시기 바랍니다.
“제어문 4형제: if, switch, for, while”
안녕하세요. 박종명입니다. 닷넷 여덟 번째 강좌를 진행하도록 하겠습니다.
이번 강좌는 C# 언어의 제어문에 대해 알아보겠습니다.
제어문은 크게 특정 조건에 따라 실행을 분기하는 조건문과 반복 실행을 위한 반복문이 있습니다. 이러한 제어문 역시 자바와 거의 차이가 없기 때문에 간략히 살펴보고 넘어가겠습니다
기본적으로 프로그램 구문의 논리적 실행방향은 위에서 아래 즉 순차적으로 실행됩니다.
그러나 간혹 이러한 순차적인 진행에 개입해서 실행 방향을 나누거나 특정 구문을 반복 실행할 필요가 있습니다.
음.. 간혹?.. 사실 ‘간혹’ 이라는 표현은 맞지 않겠네요. 대부분의 프로그램에서 제어문은 거의 필수로 요구되고 아주 자주 사용됩니다. 다들 아시겠지만.
이렇게 문장의 논리적 흐름을 제어하는 것을 제어문이라 합니다.
제어문은 특정 조건에 따라 실행을 분기시키는 조건문과 반복 실행을 시키는 반복문이 있습니다.
조건문
인생도 선택의 연속이라 했습니다.
프로그램 역시 실행되고 죽기(?)전까지의 삶 동안 많은 선택을 요구 받습니다. 인생에 있어 선택은 삶을 방향을 바꿀 수 있는 계기가 될 수도 있습니다. 이렇듯 우리가 프로그램의 생명주기 동안 그의 인생을 제어할 수 있다는 것은 아마 창조자의 기쁨(?)이지 않나 싶습니다. 부적절 한가요? 비유가? ㅎㅎ 그냥 떠들어 봤습니다 ~
1) if-else 구문
이렇듯 특정 조건에 의해 어떤 실행을 할 것인가 선택하는 것은 조건문에 의해 이루어 집니다
대표적인 조건문은 if 구문 입니다. if 문은 조건식의 참/거짓 여부에 따라 실행 문장을 선택합니다.
조건식은 true/false 를 반환하기만 하면 그 어떤 형태라도 가능합니다.
예를 들어 if(a==b), if(a > b), if(변수), if(함수) 형태를 들 수 있겠네요
기본적인 if 문은 아래와 같습니다
if(조건식){
//조건식이 참일 경우 실행할 문장
}
else{
//조건식이 거짓일 경우 실행할 문장
}
그러나 간혹 체크해야 할 조건이 두 개 이상을 경우가 있습니다. 이럴 경우 else if 구문을 이용합니다
If(조건식1){
//조건식1이 참일 경우 실행할 문장
}
else if(조건식2){
//조건식2가 참일 경우 실행할 문장
}
else{
//그 밖의 경우 실행할 문장
}
2) switch 구문
switch 역시 조건문에 해당합니다. 다만 그 사용형태가 조금 다를 뿐입니다
switch 에 체크할 대상을 두고 case 를 통해 그 대상과의 일치 여부에 따라 실행 문장을 선택합니다
그리고 각각의 case 에는 switch를 빠져 나가는 break; 문이 들어가야 합니다. 또한 어떤 조건에도 해당하지 않을 경우 default 영역이 실행됩니다. 앞서 if 구문의 else 와 그 의미가 유사한 default 구문은 생략이 가능합니다
int caseSwitch = 1
switch(caseSwitch){
case(1):
// caseSwitch = 1 인 경우 실행할 문장
break;
case(2):
// caseSwitch = 2 인 경우 실행할 문장
break;
default:
//어떤 case도 해당하지 않을 경우 실행할 문장
break;
}
한 case 에서 다른 case로 이동하기
C#에서는 C++과 같이 한 case에서 다른 case로 (암시적으로) 이동하는 것이 불가능합니다.
다만 case에 실행할 문장이 없는 경우는 가능합니다. 아래 코드를 보시죠. 결과가 어떻게 될까요?
int condition = 1;
switch (condition){
case 1:
case 2:
Console.WriteLine("1 또는 2 입니다");
break;
default:
Console.WriteLine("NaN");
break;
}
결과는 case 2 가 실행되어 콘솔에 “1또는 2입니다” 가 찍힙니다.
이상하죠? condition 은 분명 1인데 case 2가 실행됩니다.
이것은 case 1이 실행문장을 생략하여 case 2로 넘어가도록 했기 때문입니다.
이렇게 특정 case을 무시하고 바로 아래 case로 이동하고 싶을 경우 이런 형태로 사용할 수 있습니다.
다만 이런 구문은 가독성 문제가 있어 개인적으로 권장하고 싶지 않습니다.
특정 case 완전 배제하기
간혹 특정 case를 완전히 배제하고 싶은 경우가 있습니다. 이때는 case 에 실행구문을 제거하고 break; 만
사용할 수 있습니다
int condition = 1;
switch (condition){
case 1:
break;
case 2:
Console.WriteLine("조건2");
break;
default:
Console.WriteLine("NaN");
break;
}
결과는 아무것도 실행되지 않게 됩니다.
즉 case 1은 default 에도 속하지 않도록 완전히 배제하고 싶은 값일 경우 이런 식으로 사용합니다.
역시나 권장하고 싶진 않네요
반복문
인생도 어찌 보면 매 일상의 반복입니다.(또 시작이네요.. 잡설 ^^;)
while(true)
먹고,자고,출,퇴근하고
한 때 인생은 무한루프라는 생각을 한 적이 있습니다. 지겨울 때가 있었죠……
그러나 나이가 들면 들수록 루프의 조건이 만료되어 가고 있음을 느끼며 점점 초조해 지기도 합니다 ㅎㅎㅎ
1) for 구문
대표적인 반복문입니다. 조건식이 참(true)일 동안 실행을 반복하게 됩니다
반복을 위한 초기 값과 증분값을 지정할 수 있습니다. for(초기값; 조건식;증분 값)
for (int i = 1; i <= 5; i++){
Console.WriteLine(i);
}
for문의 모든 식은 선택적 요소입니다. 즉 생략 가능한데요. 아래와 같이 기술하면 무한루프가 됩니다
for(; ;)
foreach 구문
C#에서는 배열이나 컬렉션을 간단히 반복하기 위해 foreach 구문을 지원합니다
이 구문을 이용하면 for 문의 초기값이나 증가값 등을 명시하지 않고 배열의 수만큼 반복 실행됩니다
int[] numbers = { 4, 5, 6, 1, 2, 3, -2, -1, 0 };
foreach (int i in numbers){
System.Console.WriteLine(i);
}
foreach 구문은 특히 다차원 배열을 반복할 때 편리합니다
아래 코드는 2차원 배열을 탐색하는데요. 중첩 for를 이용하는 것보다 편리합니다
int[,] numbers2D = new int[3, 2] { { 9, 99 }, { 3, 33 }, { 5, 55 } };
foreach (int i in numbers2D){
System.Console.Write("{0} ", i);
}
2) while 구문
역시 유명한 반복 구문입니다. 마찬가지로 조건식이 참(true)일 동안 반복 실행합니다
while(조건식){
//반복 실행 문장
}
do- while 구문
while 의 경우 조건식을 먼저 체크하기 때문에 안에 있는 실행문장이 한번도 실행되지 않을 수 있습니다
반면 do-while 구문을 이용하면 조건식이 블록의 마지막에 정의되기 때문에 안에 있는 문장에 무조건 1번
이상은 실행되도록 합니다. 아래 코드는 조건식이 거짓이지만 한번은 실행됩니다
int i = 0;
do{
Console.WriteLine(i);
i++;
} while (i > 2);
break 와 continue
break는 반복문을 강제로 빠져 나가고 싶을 경우 사용합니다
즉 반복을 위한 조건식이 여전히 참(true)임에도 강제로 빠져 나가고 싶을 경우입니다
그리고 switch 에서도 문을 종료하는데 사용합니다.
아래 코드는 i 가 5를 초과하기 전에 2일 경우 루프를 빠져 나가도록 합니다
for (int i = 1; i <= 5; i++){
Console.WriteLine(i);
if (i == 2){
break;
}
}
continue는 반복문 안에 문장을 실행하다 말고 다음 반복으로 이동할 때 사용합니다
아래 코드는 i 가 2일 경우에는 아래 문장을 실행하지 않고 다음 반복 단계로 이동하도록 합니다
for (int i = 1; i <= 5; i++){
if (i == 2){
continue;
}
Console.WriteLine(i);
}
goto
goto는 말 그대로 지정한 위치로 점프하도록 하는 제어문입니다. 문이 goto를 만나면 바로 그 지점으로 실행을
옮깁니다. 아래 코드는 goto가 없다면 순차적으로 1,2,3 순으로 실행되지만 중간에 goto문을 만나면 2,3은
무시하고 Found라고 정의된 goto 지점으로 점프하게 됩니다
Console.WriteLine("1");
goto Found;
Console.WriteLine("2");
Console.WriteLine("3");
Found:
Console.WriteLine("GoTo");
이런 형태의 goto 문이 남발된다면 코드의 가독성은 상당히 떨어지게 됩니다.
즉 이해하기 힘든 코드가 되는 것이죠. 권장하지 않습니다
그러나 goto문이 유용할 경우가 있는데요.
중첩된 루프를 단 한방에 빠져나가고 싶을 경우 유용합니다
앞에서 살펴 본 break는 자신이 속한 루프만을 빠져나갈 수 있기 때문에 중첩이 많이 된 루프를 한번에 빠져나가기
위해서는 goto 문이 더 유용할 수 있습니다
그리고 switch구문과 함께 사용될 때 효과적입니다.
아래 코드는 case 2에서 condition 변수를 증가하여 case 1 로 다시 이동하도록 합니다
int condition = 2;
switch (condition){
case 1:
Console.WriteLine(condition);
break;
case 2:
Console.WriteLine(condition);
condition++;
goto case 1;
case 3:
Console.WriteLine(condition);
break;
default:
Console.WriteLine("NaN");
break;
}
이상으로 C#의 기본적인 제어문에 대해 알아보았습니다.
간략히 정리하려고 했는데 생각보다 글이 길어졌네요.
기본 문법을 정리하면서 이러한 제어문을 설명하지 않을 수 없어 주제를 정해 봤구요.
자바와 유사하기에 복습한다는 기분으로 훑어 보면 될 것 같습니다
그럼 좋은 한 주 되세요~~
'SW개발' 카테고리의 다른 글
| [C# 기초강좌] 10. C# 생성자와 소멸자 (0) | 2023.11.02 |
|---|---|
| [C# 기초강좌] 9. C# 배열 (2) | 2023.11.02 |
| [C# 기초강좌] 7. 박싱과 언박싱 (6) | 2023.11.02 |
| [C# 기초강좌] 6. C# 자료형 (1) | 2023.11.01 |
| [C# 기초강좌] 5. C#응용프로그램의 기본 골격 (1) | 2023.11.01 |
이 글은 제가 과거에 운영했던 사이트인 http://dotnet.mkexdev.net 의 글을 옮겨온 것입니다. 원본 글은 2010년에 작성되었습니다.
그 전에 운영했었던 사이트(mkex.pe.kr)은 흔적도 없이 사라 졌습니다. 그속의 글들도 모두... 그래서 이 사이트도 사라지기 전에 옮기고 싶은 글을 조금씩 이 블로그로 이동시키려 합니다.
(원본글) http://dotnet.mkexdev.net/Article/Content.aspx?parentCategoryID=1&categoryID=5&ID=671
이 글은 닷넷 기초 지식을 전파하기 위해 2010경에 작성되었으며, 당시 윤성우의 프로그래밍 스터디그룹 네이버 카페에도 필진으로 참여하여 연재했던 글이기도 합니다. 현재 시점에서 조금 달라진 부분이 있을 수 있으나 기본 원리와 언어 기초에 해당하는 부분은 크게 변하지 않았을 것으로 생각하며 이런 부분들을 감안해서 봐 주시기 바랍니다.
“박싱/언박싱은 성능에 좋지 않습니다”
안녕하세요. 박종명입니다. 닷넷 일곱 번째 강좌를 진행하도록 하겠습니다
지난 강좌에서 C#의 자료형에 대해 알아 보았는데요. 자료형을 학습하면서 빼 놓을 수 없는 것이 바로 자료형의 변환일 것입니다. 정수를 실수로 변환하는 등의 내용은 너무 유명(?)하기에 생략하기로 하며 이번 강좌에서는 값 형식과 참조 형식 간 변환이 일어나는 과정에 대해 알아보도록 하겠습니다.
지난 시간에 값 형식(Value Type) 자료는 스택(Stack) 메모리 영역에, 참조 형식(Reference Type) 자료는 힙(Heap) 메모리 영역에 저장된다고 배웠습니다.
이러한 값 형식과 참조 형식간에도 변환이 일어날 수 있는데요.
값 형식을 참조 형식으로 변환하는 것을 박싱(Boxing),
참조 형식을 값 형식으로 변환하는 것을 언박싱(UnBoxing)이라고 합니다
* 박싱(Boxing)
값 형식을 참조 형식으로 변환하는 것을 말하며 스택에 있는 데이터가 힙으로 복사 됩니다.
아래와 같이 값 형식인 정수형 자료 int 를 참조형식인 object 객체로 할당하게 되면 자동으로 박싱이 일어납니다.
박싱은 묵시적으로 일어나며 명시적으로 해도 무방합니다.
int = 123;
object o = i; //박싱(묵시적 변환)

스택에 있는 123이라는 정수형 자료가 힙 영역으로 복사되고 이 영역을 객체 변수 o가 가리키게 됩니다.
값 형식이 참조 형식으로 변환되었는데요. 내부적으로는 값 형식이 System.Object 형식 또는 값 형식이 구현한
인터페이스 형식으로 변환하게 됩니다.
* 언 박싱(UnBoxing)
참조 형식을 값 형식으로 변환하는 것을 말하며 힙에 있는 데이터가 스택으로 복사 됩니다
아래와 같이 박싱된 객체인 o 를 다시 값 형식으로 변환하면 언박싱이 일어납니다.
언박싱은 명시적으로 변환해 줘야 합니다
int i = 123; //값 형식
object o = i; //박싱
int j = (int) o; //언박싱(명시적 변환)

: 언박싱은 박싱한 객체에 대해서만 가능하다
주의할 것은 모든 객체가 값 형식으로 언박싱 될 수는 없습니다.
즉 이전에 값 형식을 박싱하여 생성된 객체에 한해서 언 박싱이 가능합니다.
다시 말해 아래의 코드처럼 박싱이 일어나지 않은 객체에 대한 언박싱 시도는 실패하게 됩니다.
object o = new object();
int j = (int) o; //캐스팅 예외 발생
: 언박싱은 박싱하기 전 형식을 준수해야 한다
또한 박싱 할 때의 값 형식의 타입을 준수해야 합니다.
보통 형 변환 시 short 타입을 더 큰 자료형인 int 타입으로 변환하는 것은 아무런 문제가 없습니다.
그러나 short 타입을 박싱 한 객체를 int 타입으로 언박싱 하는 것은 허용되지 않습니다.
short i = 123; //값 형식
object o = i; //박싱
int j = (int) o; //int로 언박싱 불가능
중간 언어인 IL 코드 열어보면 박싱 언박싱이 일어나는 것을 명확히 알 수 있습니다.

* 박싱/언박싱 그리고 성능
값 형식 <-> 참조 형식 즉 스택과 힙 영역을 자유로이(?) 오가는 박싱/언박싱은 무조건 좋은 걸까요?
그렇지 않습니다. 박싱/언박싱은 비용이 꽤나 많이 드는 작업임을 유념해야 합니다.
값 형식을 박싱 하는 경우 완전히 새로운 객체를 할당하고 구성해야 하며 언박싱에 필요한 캐스팅도
상당한 계산 과정이 필요합니다.
MSDN 에서는 이 과정에 대한 비용을 다음과 같이 설명하고 있습니다.
“boxing 및 unboxing 과정에는 많은 처리 작업이 필요합니다. 값 형식을 boxing할 때는 완전히 새로운 개체가
만들어져야 하며, 이러한 작업에는 할당 작업보다 최대 20배의 시간이 걸립니다. unboxing을 할 때는 캐스팅
과정에 할당 작업보다 4배의 시간이 걸릴 수 있습니다”
* 그럼 언제 그리고 왜 사용하는가?
이처럼 비용이 많이 들고 성능에 악영향을 끼치는 박싱/언박싱은 왜 지원하는 걸까요?
이유야 찾아 보면 여러 가지 있겠습니다만, 대표적으로 사용상의 편의성이라 말하고 싶네요.
C#의 모든 자료형은 System.Object 로부터 상속을 받게 됩니다.
즉 System.Object 로 데이터를 처리할 경우 특정 타입으로 인한 제약사항에서 자유로워 지게 됩니다.
이것은 배열과 같은 복합자료를 다룰 경우 유용한데요.
닷넷 프레임워크에서 제공하는 System.Collections.ArrayList 클래스는 대표적인 복합자료형 입니다.
ArrayList에 저장할 수 있는 요소의 타입은 어떤 형식이라도 상관이 없는데요. 아래 코드를 보면 ArrayList에 정수, 문자, 객체 등을 그 타입을 가리지 않고 마구(?) 추가할 수 있습니다.
System.Collections.ArrayList al = new System.Collections.ArrayList();
al.Add(123); //정수 추가
al.Add("안녕하세요"); //문자열 추가
al.Add(new Program()); //객체 추가
이것은 ArrayListy의 Add 메서드가 object 타입의 매개변수를 취하고 있기 때문입니다.
즉 object 타입이면 모두 가능하며 이 말은 곧 C#의 모든 자료형을 저장할 수 있다는 의미입니다.
이와 같이 특정 자료형에 구애 받지 않고 복합 자료를 다룰 경우 편리성을 제공하게 되는 것입니다.
(배열과 같이 동일한 타입의 자료만 저장할 수 있는 것과는 대조됩니다)
그러나 결국 al.Add(123) 과 같은 명령은 123이라는 정수형 자료가 object 타입으로 박싱이 일어나게 되며 데이터를 가져올 때에 해당 타입으로 언박싱을 해줘야 합니다
object o = al[0];
int j = (int) o;
즉 편리하기는 하지만 그 만큼의 비용은 지불해야 하는 것입니다.
또한 위와 같이 ArrayList에 여러 타입의 자료를 저장하게 되면 값을 가져올 때 박싱 되기 전 자료형으로 명확히 캐스팅을 해줘야 하기 때문에 형식에 대한 불안정성도 증가하게 됩니다.
(참고로 닷넷 2.0 부터는 이러한 ArrayList 의 단점인 고비용과 형식 불안정성을 개선하기 위해 지네릭 버전의 컬렉션을 제공하게 됩니다)
* 자바의 Wrapper 클래스
자바에서는 기본 자료형을 객체처럼 생성하기 위해서 Wrapper 클래스를 사용하게 됩니다.
아래코드는 기본 자료형 int형 정수를 Wrapper클래스인 Integer 클래스를 이용하여 객체로 생성하고 있습니다
Integer i = new Integer(123);
자바에서는 이와 같이 기본 자료형에 대한 Wrapper 클래스를 제공하는데요.
이처럼 기본 데이터 자료형을 Wrapper 객체로 생성하는 것을 박싱이라 하며 Wrapper 객체에서 기본 자료형의 값을 가져오는 것을 언박싱이라 합니다.
다만 닷넷에서는 박싱 시, 자바에서와 같이 기본자료형에 대응하는 Wrapper 클래스가 제공되는 것은 아니지만 그 동작 방식은 매우 유사하며 내부적으로 값 형식을 박싱하면 System.Object 객체로 랩핑 되거나 값 형식이 구현한 인터페이스 형식으로 묵시적 변환이 일어납니다.
따라서 자바의 Auto Boxing과 Auto UnBoxing 에 따른 편의성 제공되지는 않습니다.
다만 개념적 그리고 메모리 구조적인 측면에서는 두 언어에서의 박싱/언박싱은 거의 동일한 개념입니다.
감사합니다. 즐거운 한 주 되세요~~
'SW개발' 카테고리의 다른 글
| [C# 기초강좌] 9. C# 배열 (2) | 2023.11.02 |
|---|---|
| [C# 기초강좌] 8. C# 제어문(조건문과 반복문) (0) | 2023.11.02 |
| [C# 기초강좌] 6. C# 자료형 (1) | 2023.11.01 |
| [C# 기초강좌] 5. C#응용프로그램의 기본 골격 (1) | 2023.11.01 |
| [C# 기초강좌] 4. 명령줄 빌드 (1) | 2023.11.01 |
이 글은 제가 과거에 운영했던 사이트인 http://dotnet.mkexdev.net 의 글을 옮겨온 것입니다. 원본 글은 2010년에 작성되었습니다.
그 전에 운영했었던 사이트(mkex.pe.kr)은 흔적도 없이 사라 졌습니다. 그속의 글들도 모두... 그래서 이 사이트도 사라지기 전에 옮기고 싶은 글을 조금씩 이 블로그로 이동시키려 합니다.
(원본글) http://dotnet.mkexdev.net/Article/Content.aspx?parentCategoryID=1&categoryID=5&ID=670
이 글은 닷넷 기초 지식을 전파하기 위해 2010경에 작성되었으며, 당시 윤성우의 프로그래밍 스터디그룹 네이버 카페에도 필진으로 참여하여 연재했던 글이기도 합니다. 현재 시점에서 조금 달라진 부분이 있을 수 있으나 기본 원리와 언어 기초에 해당하는 부분은 크게 변하지 않았을 것으로 생각하며 이런 부분들을 감안해서 봐 주시기 바랍니다.
“C#은 자료는 값 타입과 참조타입으로 나누어 집니다”
안녕하세요. 박종명입니다. 닷넷 여섯 번째 강좌를 진행하도록 하겠습니다.
강좌가 좀 늦어졌네요. 개인적 사유로 조금 정신 없는 하루하루를 보내고 있네요. 죄송합니다 ^^;
이번 주제는 C# 의 자료형(Data Type)에 대해 살펴보도록 하겠습니다.
C#의 자료형 역시 자바와 크게 다르지 않습니다.
자료형은 말 그대로 자료(Data)의 형식(Type) 입니다
프로그램에서 다루고자 하는 자료가 숫자인지 문자인지를 구분하고 얼마만큼의 저장공간이 필요한지 그리고 나타낼 수 있는 최대값과 최소값은 어떻게 되는지 등의 정보가 포함되는 것이 바로 형식(Type)정보 입니다.
C#은 강력한 형식의 언어입니다.
모든 자료는 정확한 형식이 정의되어야 하며 형식에 맞도록 값이 저장되어야 합니다.
또한 자료간 형식 변환도 엄격한 기준에서 이루어지도록 하여 형식 안정성이 보장되도록 합니다
CTS(Common Type System, 공용형식시스템)
닷넷에서 이러한 형식에 관한 세부 스펙을 정의한 것을 CTS라고 합니다. CTS는 CLR에 포함된 형식 시스템으로 런타임에서 형식을 정의하고 사용 및 관리하는 기준과 방법을 정의해 놓은 일종의 사양입니다. 또한 언어간 통합에 있어 언어간 상호 작용할 수 있도록 따라야 할 규칙도 정의하고 있습니다
형식의 분류
자료 형식을 분류하는 기준은 그 관점에 따라 조금씩 달라질 수 있습니다. 보통 많이 쓰는 문자형식, 숫자형식은 언어사양에서 기본으로 제공해 주는 자료형입니다.
반면 구조체나 클래스는 사용자가 입맛에 맞게 적절히 구성할 수 있는 특수한 자료형입니다.
이런 관점이라면 ‘기본 제공 자료형 vs 사용자 정의 자료형’ 으로 분류할 수 있겠습니다
또 한편으로는, 시스템이 자료를 어떻게 처리하는지, 즉 자료의 메모리 할당 방식과 복사 메커니즘이 어떻게 되는지에 대한 관점이라면 ‘값 형식과 참조 형식’으로 분류할 수 있겠습니다.
더 세부적인 관점이 더 있겠습니다만, 더 이상은 불필요 해 보입니다. 자료형식의 분류 기준은 이렇듯 두 가지 관점에서 바로 보는 것으로 충분해 보입니다
기본제공 자료형과 사용자정의 자료형
우리가 흔히 많이 쓰는 숫자나 문자 같은 자료는 언어에서 기본으로 제공해 주는 자료형입니다. 즉 int, double, char 등의 자료형은 시스템이 미리 정의해 둔 자료형이며 이를 Built-in Type 이라고 합니다.
반면 구조체와 클래스처럼 개발자가 커스텀하게 구성할 수 있는 자료형을 사용자정의자료형이라 하는데 User-Defined Type 이라고 합니다
값 형식과 참조 형식
CTS에서는 자료 형식을 크게 값 형식(Value Type)과 참조형식(Reference Type) 두 가지로 구분하고 있습니다

값 형식은 할당된 메모리에 데이터를 직접 포함하는 형태인 반면 참조 형식은 데이터가 저장된 메모리에 대한 참조 값이 저장되는 형태(포인터와 유사) 입니다

값 형식(Value Type)
값 형식은 위 그림처럼 ‘10’이라는 자료 값이 메모리에 직접 저장되는 구조이며 스택 메모리 영역에 저장됩니다.
또한 C#의 모든 값 형식은 암시적으로 System.ValueType 클래스를 상속받게 됩니다
닷넷 프레임워크에는 기본 값 형식을 위한 구조체가 이미 정의되어 있습니다. 예를 들어 int 키워드에 해당하는 구조체는 System.Int32 이며 이 때 int 키워드는 이 구조체의 별칭입니다
값 형식 내부에서도 다른 관점으로 보면 기본 제공 자료형과 사용자 정의 자료형으로 나눌 수 있는데요.
정수, 실수, 참/거짓(부울식), 문자와 같은 값 형식은 시스템이 기본적으로 정의해 둔 자료형이며 구조체, 열거형과 같은 값 형식은 사용자가 커스텀하게 정의할 수 있는 사용자정의자료형입니다
C#에서는 기본자료형을 위한 구조체들을 미리 정의하고 있으며 사용자정의형을 위해 enum, struct 키워드를 제공합니다. 아래는 값 형식을 설명하는 표입니다
| 형식 | 설명 | 표현 가능 범위 |
| bool | 부울 값(true 또는 false) | true 또는 false |
| byte | 부호 없는 8bit 정수 | 0 ~ 255 |
| sbyte | 부호 있는 8bit 정수 | -128 ~ 127 |
| char | 유니코드 16bit 문자 | U+0000 ~ U+ffff |
| short | 부호 있는 16bit 정수 | -32,768 ~ 32,767 |
| int | 부호 있는 32bit 정수 | -2,147,483,648 ~ 2,147,483,647 |
| long | 부호 있는 64bit 정수 | -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807 |
| ushort | 부호 없는 16bit 정수 | 0 ~ 65,535 |
| uint | 부호 없는 32bit 정수 | 0 ~ 4,294,967,295 |
| ulong | 부호 없는 64bit 정수 | 0 ~ 18,446,744,073,709,551,615 |
| float | 단정밀도 32bit 부동 소수점 숫자 | -3.402823e38 ~ 3.402823e38 |
| double | 배정밀도 64bit 부동 소수점 숫자 | -1.79769313486232e308 ~ 1.79769313486232e308 |
| decimal | 10진수 128bit 값 | -79,228,162,514,264,337,593,543,950,335~ 79,228,162,514,264,337,593,543,950,335 |
| enum | 열거형 | (사용자 정의) |
| struce | 사용자 정의 구조체 | (사용자 정의) |
값 형식이 null 일 수 있나?
기본적으로 값 형식은 null 일 수 없습니다
모든 값 형식은 기본 값이 제공되어야 하며 명시적으로 기본값을 지정하지 않으면 자동으로 정의된 기본 값이 저장됩니다. 다음 표는 초기화 되지 않은 변수에 대한 자동 기본 값 목록입니다.
| 값 형식 | 기본 값 | 값 형식 | 기본 값 |
| bool | false | byte(sbyte) | 0 |
| char | ‘\0’ | decimal | 0.0M |
| double | 0.0D | enum | E(0) |
| float | 0.0F | int(uint) | 0 |
| long(ulong) | 0L | struct | 값 필드: 기본 값 참조형식 필드: null |
다만 조금 예외적인 상황이 있는데요.. 바로 nullable 타입일 경우 값 형식도 null 일 수 있습니다
nullable 타입은 닷넷 2.0 언어스펙에 추가된 내용인데요. 값 형식에도 null 을 할당할 수 있도록 하는 편리성이 추가되었습니다. ‘?’ (물음표) 키워드를 사용하여 정의하며 int?i = null 과 같이 허용됩니다
참조 형식(Reference Type)
참조 형식은 메모리에 자료 값이 직접 저장되는 것이 아니라 자료 값이 저장된 메모리에 대한 참조 값이 저장되는 구조입니다. 또한 이러한 참조 형식의 인스턴스는 힙(Heap) 메모리 영역에 저장됩니다
참조 형식 역시 기본 제공 자료형과 사용자 정의 자료형으로 구분할 수 있는데요
object 객체나 문자열을 나타내는 string 객체가 바로 닷넷이 기본으로 제공해 주는 기본 참조형식 자료입니다.
반면 클래스에 기반한 객체 및 인터페이스(interface), 델리게이트(delegate)는 사용자 정의 참조형식이라 할 수 있습니다. 또한 배열 역시 참조형식인데요. 배열의 요소가 값 형식이라 할지라도 모든 배열은 참조형식이 됩니다.
참조형식의 인스턴스는 new 연산자에 의해 메모리에 동적 할당이 되는데요.
C++ 과는 다르게 참조형식 자료의 해제는 명시적으로 개발자가 수행할 수 없습니다. 즉 닷넷 환경에서는 동적 객체의 메모리 해제는 개발자 대신 CLR의 가비지컬렉터라는 별도의 메커니즘에 의해 자동 관리됩니다.
동일성비교
두 자료가 같은 자료인지 비교하는 동일성 비교에 있어 값 형식과 참조형식은 다르게 동작합니다.
C#에서는 두 자료의 동일성 비교를 위해 ‘==’ 연산자를 제공하는데요
비교 대상 자료가 값 형식일 경우에는 자료의 값 자체를 비교하지만 참조형식인 경우에는 참조 값을 비교하게 됩니다. 아래 그림과 같이 값 형식인 두 자료 10을 비교하면 값 자체를 비교하기에 동일하다고 봅니다.

그러나 아래와 같이 참조형식일 경우에는 참조된 자료가 비록 같은 값이 가진 자료라 하더라도 참조 값이 다르기에 동일하지 않습니다.
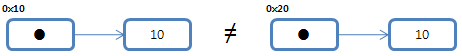
참조형식이 동일 하려면 다음과 같은 구조이어야 합니다.
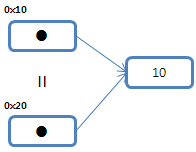
이러한 상황을 코드로 보면,
MyClass ob1 = new MyClass(10);
MyClass ob2 = new MyClass(10); //이 두 자료의 비교 ob1 == ob2 는 성립하지 않습니다
//대신
MyClass ob1 = new MyClass(10);
MyClass ob2 = ob1 //이 두 자료의 비교 ob1 = ob2 는 성립합니다
string 객체의 동일성 비교
앞서 말씀 드렸듯이 string 키워드는 문자열을 표현하기 위해 닷넷이 기본으로 제공하는 참조형식 자료입니다.
string 은 비록 참조형식 이지만 동일성 비교에 있어서는 값 형식처럼 동작합니다.
즉 string s1 =”hello” 와 string s2 = “hello” 로 선언하면 이 둘은 서로 다른 메모리에 할당되고 참조 값도 서로 다른 객체이지만 s1 = s2로 비교하면 동일하다는 결과가 나옵니다
이 것은 string 클래스 내부적으로 == 연산자를 오버로딩 하여 그 값 자체를 비교하도록 하기 때문입니다
자료 전달 및 복사
한 자료를 다른 자료에 대입하거나 함수의 매개변수로 전달할 경우 값 형식과 참조 형식은 다르게 동작합니다. 값 형식은 값 자체가 복사되어 전혀 새로운 값이 되지만 참조 형식은 참조 값이 복사되어 동일한 자료를 바라보게 됩니다.
아래 코드와 같이 int a를 선언하고 b 에 a를 대입하면 a의 값이 복사되어 b의 메모리 영역에 위치하게 됩니다. 즉 a 와 b는 각각 다른 메모리에 위치한 서로 다른 값으로써 b 값의 증가는 a 값에 영향을 주지 않습니다.
int a = 10;
int b = a;
b++;그러나 아래 코드처럼 참조형식을 대입하게 되면 참조 값이 복사되어 결국 ob1과 ob2는 같은 객체를 바라보게 됩니다. 따라서 ob2의 멤버 값 증가는 ob1의 증가와 동일하게 됩니다.
MyClass ob1 = new MyClass(10);
MyClass ob2 = ob1;
ob2.a++;이 것은 함수의 매개변수 전달에도 똑 같이 적용됩니다.
public void MyMethod(int i) 와 public void MyMethod(MyClass ob) 와 같은 형태의 함수에 각각 값 형식과 참조 형식이 전달된다고 할 경우 원리는 동일합니다. (ref 및 out 등 키워드를 사용할 경우에는 조금 달라집니다. 다음에 기회가 되면 알아보겠습니다)
지금까지 C#의 자료형에 대해 살펴보았습니다.
자료형과 관련하여 박싱/언박싱 및 가비지컬럭션, 값에 의한 전달, 참조에 의한 전달, 형 변환 등 더 다루어야 할 내용이 있으나 너무 길어지고 방대해지는 것 같아 이 정도로 정리하겠습니다.
이러한 내용들은 다음 강좌를 진행하면서 필요하면 상세히 다루도록 하겠습니다.
아래 그림은 지금까지 살펴본 자료형의 계층 구조를 보여줍니다
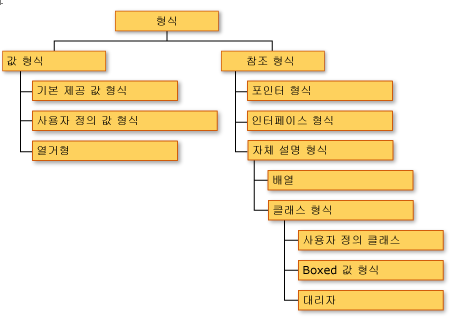
그럼 오늘 하루도 즐겁게 보내세요~~
'SW개발' 카테고리의 다른 글
| [C# 기초강좌] 8. C# 제어문(조건문과 반복문) (0) | 2023.11.02 |
|---|---|
| [C# 기초강좌] 7. 박싱과 언박싱 (6) | 2023.11.02 |
| [C# 기초강좌] 5. C#응용프로그램의 기본 골격 (1) | 2023.11.01 |
| [C# 기초강좌] 4. 명령줄 빌드 (1) | 2023.11.01 |
| [C# 기초강좌] 2. 닷넷의 실행구조 (0) | 2023.11.01 |
이 글은 제가 과거에 운영했던 사이트인 http://dotnet.mkexdev.net 의 글을 옮겨온 것입니다. 원본 글은 2010년에 작성되었습니다.
그 전에 운영했었던 사이트(mkex.pe.kr)은 흔적도 없이 사라 졌습니다. 그속의 글들도 모두... 그래서 이 사이트도 사라지기 전에 옮기고 싶은 글을 조금씩 이 블로그로 이동시키려 합니다.
(원본글) http://dotnet.mkexdev.net/Article/Content.aspx?parentCategoryID=1&categoryID=5&ID=669
이 글은 닷넷 기초 지식을 전파하기 위해 2010경에 작성되었으며, 당시 윤성우의 프로그래밍 스터디그룹 네이버 카페에도 필진으로 참여하여 연재했던 글이기도 합니다. 현재 시점에서 조금 달라진 부분이 있을 수 있으나 기본 원리와 언어 기초에 해당하는 부분은 크게 변하지 않았을 것으로 생각하며 이런 부분들을 감안해서 봐 주시기 바랍니다.
“static void Main(string[] args)”
안녕하세요. 박종명입니다. 닷넷 다섯 번째 강좌를 진행하도록 하겠습니다.
이번 주제는 닷넷의 대표적인 프로그래밍 언어인 C#의 기본 구조에 대해 알아봅니다.
Visual C#은 마이크로소프트가 닷넷 출시와 함께 탄생시킨 프로그래밍 언어입니다. 닷넷을 위한 몇 가지 언어가 존재하지만 특별한 이유가 없는 한 C#으로 시작하기를 권장합니다
HelloWorld 프로젝트를 통해 C# 응용프로그램의 기본 골격과 Visual Studio의 기본 구조에 대해 알아 보도록
하겠습니다.
이전에 설치한 Visual Studio 2008 Express Edition(이하 VS)을 실행하여 새 콘솔 응용프로그램을 생성합니다
‘파일 -> 새 프로젝트’를 실행하여 HelloWorld 라는 콘솔 응용프로그램을 만듭니다
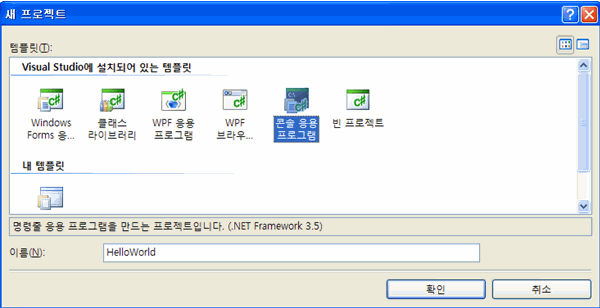
VS를 통해 생성된 프로젝트에는 Main 메서드를 포함한 클래스 및 어셈블리 참조가 자동으로 설정됩니다
아래 코드는 기본 제공되는 코드에 콘솔에 출력하는 코드가 추가된 모습입니다
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace HelloWorld
{
class Program
{
static void Main(string[] args)
{
Console.WriteLine("안녕하세요"); //콘솔창에 문자열 출력
}
}
}
Main 메서드
우선 Main 메서드에 대해 살펴보겠습니다
: 오직 하나의 ‘진입점’만 허용
Main 메서드는 응용프로그램의 진입점 역할을 하는 함수로써 닷넷 런타임에 의해 호출되는 함수입니다. 하나의 응용프로그램에는 하나의 Main 메서드만 가능합니다. (Main 메서드가 두 개 이상 존재한다면 /main:<type> 컴파일 옵션을 이용하여 진짜(?) Main을 지정해 줘야 합니다)
: 대문자 ‘M’
Main 메서드의 앞 글자 ‘M’은 반드시 대문자이어야 합니다. C# 프로그램은 기본적으로 대/소문자를 구분합니다. 소문자로 main 을 정의하면 진입점을 찾지 못합니다.
>> vs java:: Java 에서는 main 함수가 소문자이어야 합니다
: static 정의
Main 메서드는 객체가 생성되기 전에 호출되어야 하는 특징이 있으므로 static로 정의되어야 합니다. (static 은 다음에 따로 다루도록 합니다)
: void 혹은 int 반환
코드에서는 Main 메서드가 void 반환을 취하고 있습니다. 즉 반환 값이 없는 형태입니다. 일반적으로 C#응용프로그램에서는 void 반환을 사용합니다만, 경우에 따라서는 int형을 반환할 수도 있습니다.
만일 스크립트나 다른 프로그램으로 실행파일을 호출 할 경우 int 값을 반환함으로써 프로그램의 상태정보를 전달할 수 있습니다.
아래 코드는 닷넷 실행파일인 ‘HelloWorld.exe’를 배치파일로 실행하고 Main의 반환 값을 조사하는 스크립트 입니다. 이렇듯 Main을 통해 자신의 상태를 전달하고 싶을 경우 Main 함수에 int 반환을 사용하게 됩니다
rem test.bat
@echo off
HelloWorld
@if "%ERRORLEVEL%" == "0" goto good
:fail
echo Execution Failed
echo return value = %ERRORLEVEL%
goto end
:good
echo Execution Succeded
echo return value = %ERRORLEVEL%
goto end
:end
참고로 Main 메서드에 void , int 이외의 반환형식은 지원하지 않습니다
: 매개변수(string 배열)
응용프로그램이 시작될 때 특정 값을 입력 받고 싶을 경우에는 string 배열로 받을 수 있습니다 (매개변수가 없을 경우 생략 가능합니다)
아래 코드는 매개변수로 전달된 값을 출력하는 샘플입니다
static void Main(string[] args)
{
for (int i = 0; i < args.Length; i++)
{
Console.WriteLine(args[i]);
}
}
참고로 닷넷은 C++과는 달리 매개변수 string 배열의 첫 번째 요소가 실행파일 이름이 아닙니다. 즉 배열의 첫 번째 요소(args[0]) 부터 매개변수를 가르키게 됩니다
VS를 통해 매개변수를 전달하려면, ‘프로젝트 속성 -> 디버그 -> 명령줄 인수’ 에 전달할 매개변수를 입력하면 됩니다
네임스페이스
네임스페이스(namespace)는 프로그래밍 요소를 논리적으로 구분하게 하는 키워드 입니다.
HelloWorld 프로젝트에서는 굳이 네임스페이스를 지정하지 않아도 상관없으나 프로그램 크기가 커지고 협업 시 외부 어셈블리가 빈번히 사용되는 환경에서는 거의 필수에 가깝게 됩니다.
논리적으로 프로그램 구성요소를 그룹화 시킴으로써 이름 충돌을 방지하고 의미 있는 이름을 부여함으로써 어셈블리의 구성을 보다 직관적으로 관리할 수 있게 됩니다 (네임스페이스에 대해서는 다음에 따로 다루도록 합니다)
참조
어셈블리 참조
VS를 통해 프로젝트를 생성하면 우측의 ‘솔루션 탐색기’에 참조 항목이 자동 설정됩니다

참조는 말 그대로 외부에 정의된 어셈블리를 참조하는 것입니다.
이렇게 참조함으로써 외부 어셈블리의 기능을 이용할 수 있게 되는 것으로 실제로는 외부 어셈블리의 메타데이터를 참조하는 것입니다 (명령줄로 빌드 할 경우 /reference 옵션에 해당합니다)
샘플의 코드 중 콘솔 창에 출력하는 아래의 코드는 mscorlib.dll에 정의된 System 네임스페이스 하위의 Console 클래스를 이용한 것입니다
Console.WriteLine("안녕하세요");
(참고로 mscorlib.dll은 참조목록에 없는데 어떻게 된 것일까요? mscorlib.dll의 닷넷 핵심 어셈블리로 자동으로
참조가 되는 특수한 어셈블리입니다)
기본적으로 몇 개의 어셈블리가 참조되어 있습니다만 HelloWorld에서는 모두 필요한 것은 아닙니다.
다만 VS 입장에서 보편적으로 사용되는 어셈블리를 기본 참조해 두도록 되어 있습니다.
실제로 이 프로젝트에서 참조된 모든 어셈블리를 지워도 실행에 아무 지장이 없습니다
using 지시문
using 지시문은 참조한 어셈블리의 네임스페이스를 한번만 지정하여 코드에서 매번 네임스페이스를 지정 (이를 정규화된 이름이라 합니다)하지 않아도 되도록 하는 편리성을 제공합니다
예를 들어 샘플에서 Console 클래스는 System 네임스페이스에 정의되어 있으므로 전체 이름은
System.Console.WriteLine("안녕하세요");
로 되어야 하지만 using System 으로 네임스페이스를 지정했으므로 바로 클래스 명 접근이 가능하게 됩니다.
using 지시문의 또 하나의 기능은 네임스페이스에 별칭을 부여할 수 있다는 것입니다
별칭을 주기 위해서는,
using MKEX = System
와 같이 System 네임스페이스에 대한 별칭을 MKEX로 선언하여 이후 System 네임스페이스의 모든 클래스를 MKEX 별칭으로 접근 할 수 있게 합니다
이러한 별칭을 줌으로써 얻게 되는 장점은 네임스페이스가 길 경우 단축되고 의미 있는 별칭으로 관리할 수 있어 편리함과 간결함을 얻을 수 있다는 것입니다
>> vs java::
네임스페이스와 using 지시문은 자바의 패키지(package)와 import 키워드와 비교할 수 있습니다. 다만 java에서는 동일한 소스파일에서 여러 개의 패키지를 사용할 수 없지만 닷넷에서는 하나의 파일에 여러 개의 네임스페이스를 정의할 수 있는 등의 일부 차이점은 존재합니다
기본 클래스
Main 메서드를 포함하는 기본 클래스(최상위 공용클래스)의 이름은 정하기 나름입니다. VS가 자동으로 정해준 이름은 Program 이라는 클래스 입니다. 이때 이 클래스가 정의된 파일 이름 역시 정하기 나름입니다. VS에서는 기본적으로 클래스명과 같은
Program.cs 라고 명명했지만 이름을 변경해도 무관합니다
>> vs java:: 자바에서는 이와 같은 기본 클래스 이름이 파일 이름과 일치해야 합니다
이상으로 C# 응용프로그램의 기본적인 구조에 대해 살펴보았습니다.
네임스페이스, 어셈블리 참조, static 키워드 등은 그 자체만으로도 하나의 주제가 되지만 이 글에서는 자세히 다루지 않았습니다.
이 글은 기본 골격 설명에 충실하기로 하고 기회가 된다면 세세하게 살펴보도록 하겠습니다.
(기회란 니즈(needs) 겠죠? 자바 문법과 유사하여 굳이 다룰 필요가 있을 까 합니다만…)
그리고 자바와 비교하는 부분을 중간중간에 추가했습니다. 혹여 틀린 부분이 있으면 바로 지적 바랍니다.
그럼 즐거운 한 주 되세요~~~
'SW개발' 카테고리의 다른 글
| [C# 기초강좌] 7. 박싱과 언박싱 (6) | 2023.11.02 |
|---|---|
| [C# 기초강좌] 6. C# 자료형 (1) | 2023.11.01 |
| [C# 기초강좌] 4. 명령줄 빌드 (1) | 2023.11.01 |
| [C# 기초강좌] 2. 닷넷의 실행구조 (0) | 2023.11.01 |
| SBCS, MBCS, WBCS (0) | 2023.10.31 |
이 글은 제가 과거에 운영했던 사이트인 http://dotnet.mkexdev.net 의 글을 옮겨온 것입니다. 원본 글은 2010년에 작성되었습니다.
그 전에 운영했었던 사이트(mkex.pe.kr)은 흔적도 없이 사라 졌습니다. 그속의 글들도 모두... 그래서 이 사이트도 사라지기 전에 옮기고 싶은 글을 조금씩 이 블로그로 이동시키려 합니다.
(원본글) http://dotnet.mkexdev.net/Article/Content.aspx?parentCategoryID=1&categoryID=5&ID=668
이 글은 닷넷 기초 지식을 전파하기 위해 2010경에 작성되었으며, 당시 윤성우의 프로그래밍 스터디그룹 네이버 카페에도 필진으로 참여하여 연재했던 글이기도 합니다. 현재 시점에서 조금 달라진 부분이 있을 수 있으나 기본 원리와 언어 기초에 해당하는 부분은 크게 변하지 않았을 것으로 생각하며 이런 부분들을 감안해서 봐 주시기 바랍니다.
“C#컴파일러는 csc.exe 입니다”
안녕하세요. 박종명입니다. 닷넷 네 번째 강좌를 진행하도록 하겠습니다.
이번 주제는 닷넷 코드를 명령줄로 컴파일하고 실행하는 방법에 대해 알아봅니다
보통 자동완성기능이나 기본 코드 제공이 전혀 없는 환경에서 개발하는 것을 일명 ‘날코딩’ 이라고 합니다.
이와 유사한 개념으로 Visual Studio 의 도움 없이 명령(Command) 창에서 직접 컴파일러를 명시하고 실행하는 것을 저는 ‘날컴파일’이라 부르고 싶군요 ^^;
지난 시간에 .NET Framework 와 Visual Studio 2008 Express를 설치해 보았습니다
이번 시간에는 ‘명령프롬프트’(cmd.exe)를 사용해서 닷넷 코드를 직접 컴파일하고 실행하는 것에 대해 알아볼 텐데요…… 사실 Visual Studio 로 개발할 경우 컴파일러와 런타임의 위치를 모른다고 해도 알아서 컴파일하고 실행해 줍니다. 즉 IDE툴을 사용하는 경우 필요한 모든 환경 변수가 자동으로 설정되기 때문에 개발자가 일일이 경로(Path) 설정을 해 줄 필요가 없죠.
닷넷부터 시작한 많은 개발자가 환경변수를 모르고(?) 있는 까닭이기도 합니다 ^^;
어쨌든 저희는 닷넷 실행을 위한 환경변수를 직접 설정하고 코드를 실행하는 과정을 간략하게나마 살펴 보도록 하겠습니다
날컴파일(?) 해보기
1) 환경 변수 설정
이 카페의 회원 분들은 모두 환경변수 설정을 해 보았을 것으로 판단되는데요.
‘내컴퓨터 속성 -> 고급 -> 환경변수 -> 시스템변수 -> Path’ 에 해당 경로를 지정합니다
이전 강좌에 설명한대로 .NET Framework 3.5를 설치하셨다면 경로는 아래와 같습니다
Path = C:\WINDOWS\Microsoft.NET\Framework\v3.5
2) 코드 작성
간단한 C# 코드를 메모장에서 아래와 같이 작성합니다
class Program
{
static void Main()
{
System.Console.WriteLine("Hello World!");
}
}그리고 hello.cs 라는 파일명으로 저장합니다
3) 명령줄 컴파일 및 실행
닷넷은 언어별 컴파일러가 별도로 존재합니다. 저희는 C#컴파일러인 csc.exe를 사용합니다.
csc.exe 는 Path로 잡은 경로인 C:\WINDOWS\Microsoft.NET\Framework\v3.5 폴더에 위치하고 있습니다
윈도우의 cmd.exe를 실행하고 아래와 같이 컴파일 합니다
>> csc.exe hello.cs

이렇게 컴파일 hello.exe라는 IL코드가 정의된 어셈블리가 생성됩니다
이제 이 hello.exe를 아래의 명령어로 실행합니다
>> hello.exe (exe는 생략 가능합니다)

SDK 명령 프롬프트
.NET Framework 2.0부터 제공되는 명령 프롬프트인데요, 아래의 메뉴에 있습니다
‘시작 -> 프로그램 -> Microsoft .NET Framework SDK v2.0’
SDK 명령프롬프트를 사용하면 실행될 때 닷넷을 위한 각종 환경변수 설정을 자동으로 해주기 때문에 개발자가 일일이 Path를 지정해 주지 않아도 됩니다
SDK 명령 프롬프트 역시 윈도우가 제공하는 기본 명령프롬프트인 cmd.exe 가 실행되는 것인데요..
다만 내부적으로 sdkvars.bat 라는 배치파일의 명령을 수행하면서 cmd.exe 를 실행하는 것과 같습니다
sdkvars.bat 파일은 각종 환경변수를 설정하면 명령어 집합입니다.
이 파일은 C:\Program Files\Microsoft Visual Studio 8\SDK\v2.0\Bin 폴더에 있습니다.
Visual Studio 명령 프롬프트
Visual Studio 2008 정품을 설치하면 Visual Studio 2008 명령프롬프트가 제공됩니다.
이 프롬프트 역시 자동으로 환경변수를 설정해 줍니다
앞서 와 같이 cmd.exe를 실행하는 것으로, vsvars32.bat 파일을 내부적으로 수행하게 됩니다
vsvars32.bat 은 C:\Program Files\Microsoft Visual Studio 9.0\Common7\Tools 에 위치한 각종 환경변수 설정을 위한 명령어 집합입니다
이렇게 도구적으로 지원되는 명령프롬프트는 자동으로 관련 환경변수를 설정하게 되는데요
이 설정은 시스템 전역적이지는 않습니다. 즉 프롬프트가 실행된 세션에서만 환경변수가 유효하게 됩니다.
이제 모든 걸 잊어 주세요?
지금까지 날 컴파일 하는 방법과 닷넷 도구로 지원되는 명령프롬프트에 대해 알아보았습니다. 그런데 어찌 보면 이러한 내용들은 당장 샘플을 짜고 실행하고 공부하는 데에는 중요치 않을 수 있습니다. 왜냐하면 Visual Studio를 통해 개발하고 컴파일하고 실행하면 내부적으로 모든 게 자동으로 이루어 지기 때문입니다.
그러나 알아서 나쁠 것도 없습니다. 언젠가는 이와 같은 가볍지만, 세세한 지식이 도움이 될 날이 있을 것입니다. 지금 당장은 아니더라도……
참고로 컴파일러인 csc.exe는 컴파일을 위한 다양한 옵션들을 제공합니다. 이 옵션들을 한번쯤 학습하는 것을 권장 드립니다. 필요하다면 강좌를 통해 다룰 수도 있습니다만
빠른 진도(?)를 위해 생략할까 합니다
수고하셨습니다. 남은 하루 즐겁게 보내세요~
'SW개발' 카테고리의 다른 글
| [C# 기초강좌] 6. C# 자료형 (1) | 2023.11.01 |
|---|---|
| [C# 기초강좌] 5. C#응용프로그램의 기본 골격 (1) | 2023.11.01 |
| [C# 기초강좌] 2. 닷넷의 실행구조 (0) | 2023.11.01 |
| SBCS, MBCS, WBCS (0) | 2023.10.31 |
| 이런... 계집 녀(女) (6) | 2023.10.31 |
이 글은 제가 과거에 운영했던 사이트인 http://dotnet.mkexdev.net 의 글을 옮겨온 것입니다. 원본 글은 2010년에 작성되었습니다.
그 전에 운영했었던 사이트(mkex.pe.kr)은 흔적도 없이 사라 졌습니다. 그속의 글들도 모두... 그래서 이 사이트도 사라지기 전에 옮기고 싶은 글을 조금씩 이 블로그로 이동시키려 합니다.
(원본글) http://dotnet.mkexdev.net/Article/Content.aspx?parentCategoryID=1&categoryID=5&ID=666
이 글은 닷넷 기초 지식을 전파하기 위해 2010경에 작성되었으며, 당시 윤성우의 프로그래밍 스터디그룹 네이버 카페에도 필진으로 참여하여 연재했던 글이기도 합니다. 현재 시점에서 조금 달라진 부분이 있을 수 있으나 기본 원리와 언어 기초에 해당하는 부분은 크게 변하지 않았을 것으로 생각하며 이런 부분들을 감안해서 봐 주시기 바랍니다.
“닷넷 실행환경의 핵심 엔진은 CLR 입니다”
안녕하세요. 박종명입니다. 닷넷 두 번째 강좌를 진행하도록 하겠습니다
이번에는 닷넷 기반 프로그램이 어떤 과정을 통해 실행되는지 그 흐름을 살펴 보도록 하겠습니다
닷넷은 자바와 많은 부분이 닮아 있는데요. 실행 구조 역시 큰 맥락에서는 자바의 그것과 유사하다고 할 수
있겠습니다. 자 이제 닷넷의 실행 흐름의 세계로 같이 가시죠~~
닷넷 프로그램의 실행환경의 중심에 있는 것이 바로 CLR(Common Language Runtime, 공용언어런타임) 입니다.
CLR은 런타임 형식 확인,, 원시코드(Native Code) 컴파일, 코드 액세스 보안(CAS), 객체 수명 관리, 디버깅 및
프로파일링 등의 기능을 제공하여 실행환경 전반을 관리하는 핵심 엔진입니다
보통 닷넷 코드를 ‘관리되는 코드(managed code)’ 하는데요
이는 운영체제에 의해 직접 실행되지 않고 CLR에 의해 관리, 실행되는 코드를 뜻합니다
아마 닷넷을 하시다 보면 ‘관리코드’, ‘비 관리코드’ 라는 용어를 많이 접하시게 될 겁니다
이제 그림을 통해 실행 과정 하나하나를 따라가 보도록 하겠습니다

1. 우리의 모습이죠. ^^ 개발자가 닷넷 코드를 사용하여 개발합니다
2. C#으로 작성된 프로그램이 탄생했습니다
3. 프로그램을 컴파일 합니다. 이때 C# 컴파일러(csc.exe) 가 컴파일을 수행합니다
만일 VB.NET으로 작성했다면 vbc.exe라는 비주얼베이직닷넷 컴파일러가 동작합니다
즉 각 언어별 컴파일러가 따로 존재하는 것이지요
4. 컴파일의 결과물로 exe나 dll이 나왔군요. 이것을 닷넷에서는 어셈블리(Assembly)라고 부릅니다
닷넷 어셈블리의 가장 주요한 특징은 프로그램 코드 이외에 자기자신을 설명하는 메타데이터 정보가
포함되어 있다는 것입니다.그리고 확장자가 exe라고 해서 바로 실행 가능한 결과물이 아닙니다
이 어셈블리는 MSIL(Microsoft Intermediate Language) 형태를 지니고 있습니다.
MSIL은. 컴퓨터가 해석 가능한 원시코드(Native Code)가 되기 전 중간 단계의 언어입니다.
자바의 바이트 코드와 유사하다고 보시면 됩니다.
(이후 강좌를 통해 이 MSIL 코드를 직접 살펴보는 시간을 갖도록 하겠습니다)
그리고 이 exe(dll) 파일에는 소스코드 내의 클래스를 설명하는 메타데이터와 매니페스트 정보가 포함됩니다
5. 이제 MSIL 코드를 실행하고자 합니다.
지금까지는 컴파일 환경이었습니다. 이제 본격적으로 실행환경으로 넘어갑니다
6. 이제부터가 그 유명한(?) CLR 의 영역인데요.
실행을 위해 MSIL 코드가 CLR로 호스트 될 때 제일 처음 CLR 내부의 Class Loader 에 의해 어셈블리 내 클래스들의
레이아웃 로드와 메타데이터 및 사용된 클래스 라이브러리 등을 로드 하여 각종 과정(타입체크, 마샬링 등)을 거친 뒤
메모리에 로드 됩니다
7. 메모리에 올라간 어셈블리를 컴퓨터가 이해할 수 있도록 원시코드(Native Code)로 변환해야 하는데요
이 역할을 수행하는 것이 ‘JIT 컴파일러’라는 놈입니다(Just-In-Time, jitter(지터)라고 부릅니다)
JIT 컴파일러는 MSIL 코드를 특정 플랫폼 기반의 원시코드로 변환시켜 줍니다
8. 7의 과정에서 탄생한 원시코드(Native Code) 입니다
9. JIT컴파일러에 의해 컴파일 된 원시코드는 다음 번 실행을 위해 메모리에 캐시 됩니다.
즉 동일한 어셈블리가 다시 실행될 때 지금까지의 과정을 생략함으로써 실행속도의 향상을 꾀합니다.
따라서 다음 번 실행 시에는 여기서부터 출발합니다
10. 이제서야 우리가 작성한 프로그램을 모니터를 통해 눈으로 확인 할 수 있게 되었군요.
축하 드립니다 ^^;
어떤가요? 자바의 실행구조와 유사함을 느끼시나요?
사실 이러한 실행구조는 자바를 모방했다기 보다는 플랫폼 독립성을 위한 메커니즘이라고 봅니다
지금까지 닷넷의 개요와 역사 그리고 실행 구조에 대해 간략히 살펴 보았습니다
다음 강좌에서는 본격적으로 닷넷 개발을 위한 개발 환경 설치를 해 보도록 하겠습니다
수고하셨습니다~~
'SW개발' 카테고리의 다른 글
| [C# 기초강좌] 5. C#응용프로그램의 기본 골격 (1) | 2023.11.01 |
|---|---|
| [C# 기초강좌] 4. 명령줄 빌드 (1) | 2023.11.01 |
| SBCS, MBCS, WBCS (0) | 2023.10.31 |
| 이런... 계집 녀(女) (6) | 2023.10.31 |
| 다차원 배열의 인덱싱 (0) | 2023.10.27 |
이 글은 제가 과거에 운영했던 사이트인 http://dotnet.mkexdev.net 의 글을 옮겨온 것입니다. 원본 글은 2009년 10월에 작성되었습니다.
그 전에 운영했었던 사이트(mkex.pe.kr)은 흔적도 없이 사라 졌습니다. 그속의 글들도 모두... 그래서 이 사이트도 사라지기 전에 옮기고 싶은 글을 조금씩 이 블로그로 이동시키려 합니다.
(원본글) http://dotnet.mkexdev.net/Article/Content.aspx?parentCategoryID=2&categoryID=9&ID=525
문자 인코딩 체계(방식)에 대한 분류입니다.
SBCS(Single Byte Character Set)
1바이트로 문자를 인코딩합니다. ASCII 인코딩이 대표적인 SBCS 입니다
ASCII 개요와 코드표는 다음의 글을 참고해 주세요.
=> ASCII
MBCS(Multi Byte Character Set)
1바이트로는 최대 256 글자만 표현할 수 있기 때문에 영어권 이외의 나라에서는 그 나라 문자를 인코딩 할 수 없기 때문에 바이트를 하나 더 사용합니다. 즉 최대 2바이트로 인코딩 합니다. 2바이트로 문자를 표현하기 때문에 DBCS(Double Byte Character Set)이라고도 합니다.
다만 MBCS 는 무조건 2바이트가 아니라 영어와 같이 1바이트로 표현 가능한 문자는 여전히 1바이트 사용합니다.
즉 문자에 따라 1byte 혹은 2byte 를 사용합니다(MBCS = SBCS + DBCS라 할 수 있습니다)
대표적으로 euc-kr 이나 한글 윈도우 기본 ANSI 인코딩은 코드페이지 949가 MBCS에 해당합니다
euc-kr 전체 코드표는 다음의 링크를 참조해 주세요
=> euc-kr 전체 코드표
WBCS(Wide Character Set)
MBCS 는 각 나라마다 그 정의가 다릅니다
따라서 전 세계 글자를 하나의 코드표로 정의하는게 필요 했는데, 바로 그렇게 탄생한 것이 유니코드(UniCode) 입니다. 유니코드를 WBCS라 합니다
유니코드에 대한 저의 에피소드는 다음글을 참조해 주세요
=> 이런... 계집 녀
아래 그림은 대표적인 인코딩에 따른 문자 길이와 바이트 수, 그리고 코드페이지를 보여줍니다
(닷넷으로 작성된 프로그램 입니다)

소스참고---------------------------------------------------------------------------
private void btnDefault_Click(object sender, EventArgs e)
{
this.txtDefaultLenght.Text = str.Length.ToString();
this.txtDefaultByte.Text = Encoding.Default.GetByteCount(str.ToCharArray()).ToString();
//this.txtDefaultByte.Text = Encoding.GetEncoding("ks_c_5601-1987").CodePage.ToString();
this.txtDefaultCodePage.Text = Encoding.Default.CodePage.ToString();
}
private void btnUnicode_Click(object sender, EventArgs e)
{
this.txtUnicodeLength.Text = str.Length.ToString();
this.txtUnicodeByte.Text = Encoding.Unicode.GetByteCount(str.ToCharArray()).ToString();
//this.txtUnicodeCodePage.Text = Encoding.GetEncoding("utf-16").CodePage.ToString();
this.txtUnicodeCodePage.Text = Encoding.Unicode.CodePage.ToString();
}
private void btnUTF8_Click(object sender, EventArgs e)
{
this.txtUTF8Length.Text = str.Length.ToString();
this.txtUTF8Byte.Text = Encoding.UTF8.GetByteCount(str.ToCharArray()).ToString();
//this.txtUTF8CodePage.Text = Encoding.GetEncoding("utf-8").CodePage.ToString();
this.txtUTF8CodePage.Text = Encoding.UTF8.CodePage.ToString();
}
private void btnEucKr_Click(object sender, EventArgs e)
{
this.txtEucLength.Text = str.Length.ToString();
this.txtEucByte.Text = Encoding.GetEncoding("euc-kr").GetByteCount(str.ToCharArray()).ToString();
this.txtEucCodePage.Text = Encoding.GetEncoding("euc-kr").CodePage.ToString();
}
----------------------------------------------------------------------------------
참고>
* chcp
현재 운영체제의 기본 ANSI 코드 페이지를 확인하려면 Command 창에서 다음 명령어를 확인하세요
chcp : 현재 활성 코드 페이지 확인
chcp xxx : 코드 페이지 변경

* charmap
그리고 현재 운영체제의 유니코드 문자표를 확인하려면 Command 창에서 charmap 명령어로 확인하세요

'SW개발' 카테고리의 다른 글
| [C# 기초강좌] 4. 명령줄 빌드 (1) | 2023.11.01 |
|---|---|
| [C# 기초강좌] 2. 닷넷의 실행구조 (0) | 2023.11.01 |
| 이런... 계집 녀(女) (6) | 2023.10.31 |
| 다차원 배열의 인덱싱 (0) | 2023.10.27 |
| 배열 인덱싱의 메커니즘(arr[i] == *(arr+i)) (2) | 2023.10.27 |
이 글은 제가 과거에 운영했던 사이트인 http://dotnet.mkexdev.net 의 글을 옮겨온 것입니다. 원본 글은 2008년 10월에 작성되었습니다.
그 전에 운영했었던 사이트(mkex.pe.kr)은 흔적도 없이 사라 졌습니다. 그속의 글들도 모두... 그래서 이 사이트도 사라지기 전에 옮기고 싶은 글을 조금씩 이 블로그로 이동시키려 합니다.
(원본글) http://dotnet.mkexdev.net/Article/Content.aspx?parentCategoryID=3&categoryID=26&ID=400
제목보고 놀라셨나요? ㅎㅎ
상소리(?) 같아서 기분이 상하신 분은 양해 바랍니다.
프로젝트 진행 중 '계집 녀(女)'라는 한자와 관련해서 경험한 재미있는 에피소드가 있어 이를 소개하려 합니다.
저는 게임회사를 다니고 있습니다.
저희 팀에서는 데이타베이스도 관리하고 있기 때문에 회원 DB를 직접 관리합니다.
어느날,
게임개발팀 팀장으로부터 닉네임이 중복된다는 제보(?)를 받게 됩니다.
우리 게임은 정책적으로 닉네임은 완전 고유해야 하거든요, 그리고 이를 시스템에 적용한 상태이구요
웹 사이트에서 회원 가입 시 중복 체크를 하고 있습니다.
물론 DB에서도 유니크 제약조건이 걸려 있어서, 같은 닉네임이 입력될 여지는 전혀 없는 것이지요.
그런데, 제보받은 두 명의 회원 닉네임을 보니, 정말 같아 보였습니다.
저희는 닉네임에 한자도 입력 가능하기 때문에, 두 회원의 닉네임은 한자였습니다.
그리고 그 한자 중간에는 '계집 녀(女)'가 들어 있었지요. 다음과 같이요...
회원 1 의 닉네임 : XXX女XXX
회원 2 의 닉네임 : XXX女XXX
이런, 어떻게 같은 닉네임이 DB에 입력되었을까???
닉네임 문자를 가만히 들여다 보니, 女 자가 살짝, 아주 살짝 달라보입니다.
女 / 女 <- 달라 보이나요?
메모장에서 확대를 해 봤습니다. 그랬더니, 오히려 더 같은 글자로 보이네요.

확대하기 이전 두 글자는 살짝 차이가 보이는데, 확대를 하니 오히려 완전 같은 글자처럼 보이는 군요.
여튼, 두 글자가 다른 글자일 수도 있겠구나.. 하며 문자코드를 봤습니다.
참고로, 저희 웹 사이트와 DB는 국제 표준 유니코드를 사용합니다.
두 한자의 유니코드를 보니, 이런!!!
코드가 서로 다르군요. 즉 유니코드 테이블에서는 두 글자가 서로 다른 글자로 엄연히 자리하고 있던 것입니다.
'녀'가 '여'로 발음되는 것은 두음법칙에 의해서 인데, 이러한 규칙이 국제표준코드 정의에도 그대로 적용되어 있다니. 놀랍습니다. ㅎㅎ;
결과적으로 사람이 보기에, 그리고 의미상으로는 같은 두 한자가, 시스템은 다른 글자로 인식하기 때문에
중복없이 DB에 저장된 것입니다.
한자 사전을 찾아 봤습니다. 두 글자가 떡 하니(?) 나오네요 --;

참고로 유니코드 표에서 두 글자의 16진수 10진수 코드는 다음과 같습니다.
16진수 10진수
女(여) : F981 63873
女(녀) : 5973 22899
두음법칙이 적용되는 한자는 모두??
그렇습니다. 두음법칙이 적용되는 한자는 모두, 이러한 현상이 발생합니다.
'어질 량(良) / 어질 양(良)' 도 두음법칙에 의해 서로 다르게 발음되며, 이에 대한 유니코드도 다릅니다.
그리고 '년(年)과 연(年)' 도 있지요.
또 뭐가 있을까요? 다음을 참고하세요..
제10항: 한자음 ‘녀, 뇨, 뉴, 니’가 단어 첫머리에 올 적에는 두음 법칙에 따라 ‘여, 요, 유, 이’로 적는다.
제11항: 한자음 ‘랴, 려, 례, 료, 류, 리’가 단어의 첫머리에 올 적에는 두음 법칙에 따 라 ‘야, 여, 요, 유, 이’로 적는다.
다만, 모음이나 ‘ㄴ’받침 뒤에 이어지는 ‘렬, 률’은 ‘열, 율’로 적는다.
혹시, 당신의 응용프로그램에서도 고유한 성질의 필드에 한자를 입력받고 있으신가요?
그렇다면, 이러한 중복아닌 중복마저도 허용치 않으려면 이런 현상을 미리 고려하셔야 겠네요
아니라면, 그냥 재미삼아.. 이럴 수도 있겠구나.. 하면 되겠지요 ~~
'SW개발' 카테고리의 다른 글
| [C# 기초강좌] 2. 닷넷의 실행구조 (0) | 2023.11.01 |
|---|---|
| SBCS, MBCS, WBCS (0) | 2023.10.31 |
| 다차원 배열의 인덱싱 (0) | 2023.10.27 |
| 배열 인덱싱의 메커니즘(arr[i] == *(arr+i)) (2) | 2023.10.27 |
| 배열과 포인터(Pointer) 의 상관관계 (2) | 2023.10.27 |
이 글은 제가 과거에 운영했던 사이트인 http://dotnet.mkexdev.net 의 글을 옮겨온 것입니다. 원본 글은 2008년 5월에 작성되었습니다.
그 전에 운영했었던 사이트(mkex.pe.kr)은 흔적도 없이 사라 졌습니다. 그속의 글들도 모두... 그래서 이 사이트도 사라지기 전에 옮기고 싶은 글을 조금씩 이 블로그로 이동시키려 합니다.
(원본글) http://dotnet.mkexdev.net/Article/Content.aspx?parentCategoryID=2&categoryID=9&ID=106
『 다차원 배열의 인덱싱 』
앞서 arr[3] 과 같은 1차원 배열에서의 인덱싱 기법을 알아 보았다.
만일 arr[2][2] 와 같은 2차원 배열이라면 어떤 메커니즘으로 각 요소를 찾아 낼 수 있을 것인가?
눈치 챘을 수도 있지만 원리는 1차원 배열과 완전 동일하다.
1차원 배열과 마찬가지로 아래의 내용이 핵심이다.
“배열은 연속된 메모리 공간에 순차적으로 저장된다”
이것은 2차원이든 3차원이든 모두 동일한 원칙이다.
만일, arr[2][2] 라는 2차원 배열이 있다면 2행 2열의 배열로써 편의상 아래와 같은 표현으로 인식했다.

그러나 실제 메모리에서는 연속된 메모리 공간에 값을 저장하게 된다. 아래 그림처럼..

즉, 다차원 배열 역시 연속된 공간에 순차적으로 저장되는 자료구조이기 때문에 1차원 배열과
유사한(사실은 동일한) 포인터 연산으로 각 요소에 접근할 수 있게 되는 것이다.
그럼 샘플 하나를 보고 이해해 보자.
arr[2][2] 로 정의된 배열의 arr[1][1] 의 요소를 찾는 연산은 아래와 같다.
a [1][1] = *( arr + ((1 * 2) * 4byte) + (1 * 4byte) ) = *(arr + 8 + 4) = *(arr + 12)
배열의 첫 요소를 가리키는 arr 상수 포인터가 0x20을 가리키므로 arr 에서 12 byte 이동한 메모리인 0x32 를 포인팅하게 되는 것이다.
위의 식이 복잡해 보인다면 int 형 배열이기 때문에 자동으로 곱해 지는 4byte 를 생략해서 생각해 보자.
a[1][1] = *(arr + (1 * 2) + 1 ) = *(arr + 2 + 1) = *(arr + 3) 가 되어 3칸을 이동하게 되는 것이다 (int 형 메모리의 한 칸은 4byte 이므로 3칸이라 함은 12byte 이다)
1차원 배열과 조금 다른 점은 배열의 ‘열 정보’ 즉 열 값을 곱해 주는 것이다.
Arr[2][2] 의 열 값은 2이다
메모리 구조를 보면 당연한 것이다
행과 열을 가진 배열은 순차적으로 행 단위로 저장이 되기 때문에 열의 숫자를 곱해 줘야 그만큼 메모리
이동이 가능한 것이다 ( (0,0) -> (0,1) -> (1,0) -> (1,1) ... )
아래 그림은 내부적으로 곱해 지는 4byte 를 제외한 상태에서 쌍으로 색깔로 매핑 시킨 것이다.
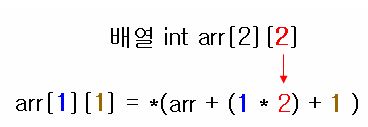
참고로 다차원 배열을 포인터로 표현해 보자.
앞서 배열은 포인터이므로, 1차원 배열은 int *p = arr 이 로 표현된다고 하였다.
다차원 배열은 다음과 같이 표현되어야 배열과 포인터가 서로 같다고 할 수 있다
int (*p)[열];
즉, int arr[2][2] 일 경우
int (*p)[2] = arr 이 성립되는 것이다
이과 같이 정의된 포인터 p 를 배열 포인터라 한다
주의> 배열 포인터와 포인터 배열을 혼동하지 말기 바란다.
포인터 배열은 int *p[2] = {&a, &b} 와 같이 포인터 자체를 여러 개 가진 것을 말하는 것이다
(괄호의 유/무가 이런 엄청난 차이를 보이네요 ^^; )
이로써 다차원 배열의 인덱싱 메커니즘을 알아 보았다.
이것은 2차원뿐만 아니라 3차원 이상에서도 동일한 메커니즘이다.
'SW개발' 카테고리의 다른 글
| SBCS, MBCS, WBCS (0) | 2023.10.31 |
|---|---|
| 이런... 계집 녀(女) (6) | 2023.10.31 |
| 배열 인덱싱의 메커니즘(arr[i] == *(arr+i)) (2) | 2023.10.27 |
| 배열과 포인터(Pointer) 의 상관관계 (2) | 2023.10.27 |
| 리터럴(Literal) 상수 (1) | 2023.10.27 |
